
Meine Firewall spricht mit mir – Check Point Infinity AI Copilot und Fortinet Advisor

Heutzutage wird es immer wie schwieriger, eine komplexe Firewall-Infrastruktur zu administrieren. Führende Sicherheitshersteller entwickeln daher innovative KI-Assistenten, welche die Administration vereinfachen sollen. Zwei aktuelle Beispiele sind der Check Point Infinity AI Copilot sowie der Fortinet Advisor. Diese neuen spannenden Features versprechen, die Produktivität bei der Firewall-Verwaltung durch Automatisierung und fortschrittliche Analysen zu steigern. Ich möchte in diesem Blog beide Lösungen vorstellen und aufzeigen, wohin diese Reise gehen könnte.
Problem: Fachkräftemangel
Die Security-Abteilungen stehen heutzutage vor mehreren Herausforderungen. Einerseits gibt es einen Mangel an Fachkräften und Ressourcen, andererseits sinken die Budgets. Laut einem kürzlich veröffentlichten Bericht bleiben IT-Sicherheitsstellen oft bis zu einem halben Jahr unbesetzt.
Hier kommt die Künstliche Intelligenz ins Spiel, die den Mitarbeitenden Arbeit abnehmen wird.
Check Points Antwort: «Infinity AI Copilot»
Check Point hat auf diese Herausforderungen reagiert und ist am Entwickeln des «Infinity AI Copilot». Auf der CPX in Wien wurde dieser bisher als Preview vorgestellt. Aktuell läuft die Funktion nur in Kombination mit einem Smart-1 Cloud Management. Ab Mitte Jahr soll der Co-Pilot auch in On-Premises Managements integriert werden.
Es handelt sich im Grunde wirklich um Microsofts «Copilot» – oder besser: Er basiert auf OpenAIs LLM (Large Language Model) ChatGPT. Die Implementierung soll von Grund auf sicher sein, d.h. Microsoft habe keinen Zugriff auf Daten oder Logs, da der «Infinity AI Copilot» getrennt in einer «Sandbox» in der Cloud-Infrastruktur von Check Point laufe. Nachprüfen kann ich dies nicht, aber ich gehe mal davon aus, dass sich Check Point gewisse Gedanken dazu gemacht hat.
Quelle: youtu.be/qEDcuLt7J4I?si=q6W0DVIpALsKTMaL&t=91 , abgerufen am 11.03.2024
Was ist der Nutzen?
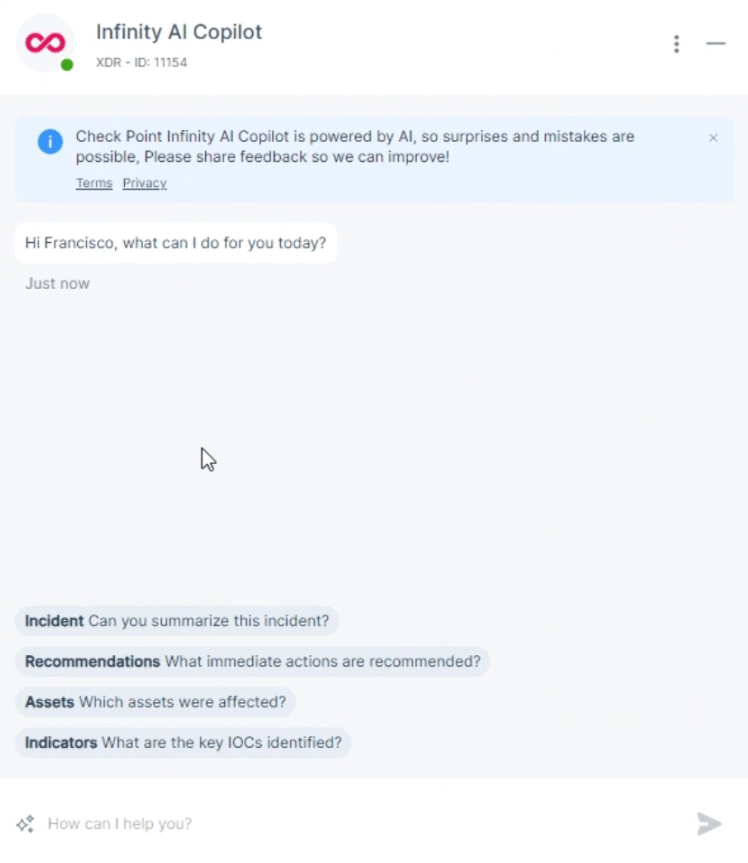
Grundsätzlich ist das Ziel, durch Künstliche Intelligenz dem Security Admin und dem Security Analyst die Arbeit zu erleichtern. Ähnlich wie Microsofts Copilot kann man in natürlicher Sprache Fragen stellen, Logs analysieren, Statistiken erstellen und sogar die Policy installieren lassen.
Der Copilot hat via API-Schnittstelle Zugriff auf die Firewall Rulebase, IPS-Datenbank, auf die Logs, Events und Reports sowie auf die Secure-Knowledge-Datenbank.
Hier einige Beispielfragen und Anweisungen:
- Bin ich gegen die Attacke (CVE-2024-xxxx) geschützt?
- Gib mir eine kurze Zusammenfassung, unterteilt nach den Attack-Phasen
- Zeige mir die Top IPs, welche auf den Host A zugegriffen haben.
- Weshalb konnte User X nicht auf SAP zugreifen?
- Füge User X der SAP-User-Gruppe hinzu
- Installiere die Policy
Aus meiner Sicht eine sehr interessante Art und Weise, mit seiner Firewall-Umgebung zu kommunizieren. Besonders sinnvoll wird es, wenn viele Firewalls vorhanden sind und über alle Firewalls Abfragen gemacht werden. Als eindrückliches Beispiel von der CPX ist mir die IPS-Policy-Abfrage geblieben, als untersucht wurde, auf welcher Firewall die IPS-Signatur XY nicht aktiviert wurde.
Die Check-Point-Mitarbeitenden meinten, dass man so schneller die wichtigen Informationen finden könne und plötzlich neue Anwendungsfälle auftauchten. Es bestehe auch die Gefahr, dass man sich zu lange mit den Abfragen beschäftigt und die Zeit vergisst.
Weiter kann ich bestätigen, dass verschiedene Sprachen unterstützt werden. Unter anderem kann man sich mit dem Firewall-Copiloten auch auf Deutsch, Französisch und Englisch unterhalten.
Infinity AI Copilot in einem Video
Bisher gibts keine offiziellen Videos, aber ich habe hier ein spanisches Video gefunden, in welchem der Infinity AI Copilot beispielhaft vorgestellt wird: https://www.youtube.com/watch?v=qEDcuLt7J4I
Fortinets Antwort «Fortinet Advisor»
Ähnlich wie Check Point hat auch Fortinet eine Lösung entwickelt: den Fortinet Advisor. Dieser Assistent kann ebenfalls eine Reihe von Aufgaben übernehmen und so die Security-Analysten und Threat Hunters entlasten. Aktuell ist der Fortinet Advisor auch in der Preview-Phase und bisher nur in den Lösungen FortiSIEM und in FortiSOAR integriert.
Mittels Fortinet Advisor können Sicherheitsvorfälle rascher interpretiert werden, komplexe Analysen in natürlicher Sprache gestellt werden und es können sogar Vorschläge für die Reaktion auf Bedrohungen abgerufen werden.
Hier zwei Fortinet-Advisor-Demo-Videos:
- FortiSIEM: https://www.youtube.com/watch?v=JGyr0xNPN2M
- FortiSOAR: https://www.youtube.com/watch?v=gtDskE9bSUc
Wie nützlich und sinnvoll ist das wirklich?
Die Frage, wie nützlich diese KI-gestützten Systeme wirklich sind, hängt von verschiedenen Faktoren ab. Sie können zweifellos dazu beitragen, die Arbeitslast der IT-Sicherheitsmitarbeitenden zu verringern und die Effizienz zu steigern. Aber wie effektiv sie in der Praxis sein werden, wird sich erst noch zeigen. Vermutlich wird es auch eine gewisse Eingewöhnungsphase geben, bis jeder für sich den richtigen Umgang mit diesen neuen KI-Tools gefunden haben wird.
Was bringt die Zukunft?
Natürlich ist man zuerst sehr begeistert von den neuen Möglichkeiten der Administration und Kommunikation mit der Firewall. Rasch sind mir auch weitere sinnvolle Use Cases eingefallen.
Ich würde mir zum Beispiel wünschen, dass zukünftig die KI-Assistenten auch die Firewall-Regeln überprüfen könnten oder sogar vorschlagen würden, welche Optimierungen möglich wären. Oder eine API-Schnittstelle, mit welcher ich in verständlicher Sprache Abfragen machen könnte.
Zukünftig soll, gemäss Check Point, der Infinity AI Copilot mit allen Check-Point-Lösungen (z.B. E-Mail, Endpoint usw.) funktionieren. Selbst Zugriffe oder Abfragen auf Support Cases sollen möglich sein.
Ich denke, die Zukunft wird spannend!
Mein Fazit
Zusammenfassend lässt sich sagen, dass KI-gestützte Systeme wie der «Infinity AI Copilot» von Check Point und der «Fortinet Assistant» von Fortinet das Potenzial haben, die IT-Sicherheitsbranche zu revolutionieren. Sie könnten dazu beitragen, die Arbeitslast der Mitarbeitenden zu verringern und die Effizienz zu steigern. Es bleibt abzuwarten, wie sie sich in der Praxis bewähren werden.
Weitere Informationen
Check Points Press Release zu Infinity AI Copilot: www.checkpoint.com/de/press-releases/check-point-software-unveils-infinity-ai-copilot-transforming-cyber-security-with-intelligent-genai-automation-and-support
Interessierte Smart-1-Cloud-Kunden können sich zum Preview-Programm anmelden: www.checkpoint.com/ai/copilot
Fortinet-Advisor-Produktseite: https://www.fortinet.com/products/fortiai
Weiterführende Links
Der Beitrag Meine Firewall spricht mit mir – Check Point Infinity AI Copilot und Fortinet Advisor erschien zuerst auf Tec-Bite.

SEPPmail: Cloud oder On-Premises?

SEPPmail ist ein Secure E-Mail Gateway, das E-Mail-Verschlüsselung, E-Mail-Signatur und Übertragung von grossen Dateien bietet. Grundsätzlich offeriert SEPPmail zwei Arten der Implementation: On-Premises und SEPPmail Cloud. In diesem Artikel werden die Unterschiede zwischen diesen beiden Implementationsmöglichkeiten diskutiert.
On-Premise SEPPmail Appliances
SEPPmail On-Premises Appliances sind physische oder auch virtuelle Appliances, die im Rechenzentrum einer Organisation installiert sind.
Es können auch virtuelle Instanzen in Azure oder AWS oder auf eine Plattform, auf welcher ein entsprechendes Image installiert werden kann, aufgesetzt und betrieben werden. Diese Appliances ermöglichen einem Unternehmen, die eigene E-Mail-Kommunikation zu schützen, die Bereitstellung dieses Schutzes zu vereinfachen und gewährleisten alle Funktionen der SEPPmail Secure-E-Mail-Lösung. Die Vor-Ort-Geräte sind einfach zu installieren und zu konfigurieren und bieten eine vollständige Kontrolle über die E-Mail-Sicherheitsinfrastruktur. Diese Art, die Lösung von SEPPmail bereitzustellen, ist für Organisationen geeignet, die eine vollständige Kontrolle über ihre E-Mail-Sicherheitsinfrastruktur benötigen und über die erforderlichen Ressourcen zur Verwaltung und Wartung der Appliances verfügen.
SEPPmail Cloud
Seit 2022 bietet SEPPmail mit der SEPPmail Cloud zudem eine cloudbasierte E-Mail-Sicherheitslösung, die alle Funktionen der SEPPmail Secure-E-Mail-Lösung ermöglicht. SEPPmail Cloud ist eine kosteneffektive Lösung, welche die Notwendigkeit einer On-Premises-Installation beseitigt. Die cloudbasierte Lösung ist einfach zu bedienen und gewährt das gleiche Sicherheitsniveau wie die On-Premises Appliances. SEPPmail Cloud wird von SEPPmail in Rechenzentren in der Schweiz und Deutschland betrieben und erfüllt vollständig die aktuellen Datenschutzstandards wie die DSGVO.
Es gibt in der Cloud kleinere Einschränkungen bei den Konfigurationsmöglichkeiten, die den Administratoren über das Portal und in der Wahl der Zertifikatsautorität für das Ausstellen von Benutzer-Zertifikaten zur Verfügung gestellt werden. Auch besteht zum jetzigen Zeitpunkt keine Möglichkeit, in der Cloud eigene Directory Services über LDAP anzusprechen. Dafür hält die SEPPmail Cloud aufgrund der technischen Möglichkeiten einen verbesserten Filter gegen Spam, Phishing und Malware bereit. Diese ist für Unternehmen aller Grössen geeignet und ermöglicht eine kosteneffektive und zuverlässige E-Mail-Sicherheitslösung.
Unterschiede zwischen On-Premises Appliances und SEPPmail Cloud
Der Hauptunterschied zwischen den beiden Implementationsarten besteht darin, dass On-Premises Appliances im Rechenzentrum einer Organisation installiert sind und selbständig betrieben und gewartet werden müssen, während SEPPmail Cloud eine cloudbasierte Lösung ist, die von SEPPmail selbst betrieben wird.
Weiter gibt es auch Unterschiede in Bezug auf die Lizenzierung, welche sich zwischen den Bereitstellungsmöglichkeiten unterscheidet. Während die On-Premises-Appliances-Lizenzen für eine bestimmte Anzahl User erworben werden müssen, werden die effektiv genutzten Services in der Cloud jeweils auf Monatsende abgerechnet. Dies führt für die Cloud zu einer erhöhten Flexibilität in Bezug auf die Anzahl der effektiven User, kann aber aufgrund des bereits erwähnten Fehlens von LDAP auch dazu führen, dass im Vergleich zu einer On-Premises-Lösung ein höherer Bedarf an Userlizenzen entsteht.
Die SEPPmail Cloud bietet den zusätzlichen Vorteil, dass keine Appliances mehr in den eigenen Rechenzentren bzw. den eigenen Virtual Hosts betrieben werden müssen, was den dadurch entstandenen Aufwand massiv reduziert oder gar eliminiert.
Abschliessend kann gesagt werden, dass die Wahl zwischen On-Premises Appliances und SEPPmail Cloud von den spezifischen Anforderungen einer Organisation, sowohl in Bezug auf die gebotenen Konfigurationsmöglichkeiten, dem passenden Lizenzmodell, als auch von den Ressourcen, welche für Wartung und Betrieb der Lösung zur Verfügung stehen, abhängt. Es lohnt sich, genauere Bedarfsabklärungen vorzunehmen, um zu schauen, ob die SEPPmail Cloud genügt oder man sich den Einschränkungen bewusst ist und damit leben kann.
Der Vorteil der SEPPmail Cloud ist, dass man das Setup im Pfad mit dem guten Spam- bzw. Viren-Filter besser unterstützen kann, weil damit als erster MTA eine gute Lösung verfügbar ist. In der On-Premises-Umgebung ist das Protection Pack (Antispam/Antivirus) nicht für alle Bedürfnisse geeignet.
Weiterführende Links
UNCODE.initRow(document.getElementById("row-unique-0"));
Der Beitrag SEPPmail: Cloud oder On-Premises? erschien zuerst auf Tec-Bite.

Was ist eigentlich ZTNA 2.0?

Die Geschichte und Prinzipien von Zero Trust reichen bis in die 1990er-Jahre zurück, als der Begriff erstmals in einer Doktorarbeit eines gewissen Stephen Paul Marsh geprägt wurde. Mit der 2018 Publikation «Zero Trust Architecture» des National Institute of Standards and Technology (NIST) erhielt die Wortschöpfung grössere Bedeutung. Zero Trust hat sich unlängst als ein ideales Framework zur Absicherung von geschäftlichen Usern, Workloads und Geräten zu einer hochrangig verteilten, mobilen und Cloud-zentrierten Unternehmenslandschaft etabliert. Es besteht jedoch immer die Gefahr, dass «SASE» und «Zero Trust» als Marketing Buzzwords überstrapaziert werden, da allein die Bereitstellung von Zero-Trust-Sicherheitsdiensten über die Cloud das Konzept der SASE-Architekturen hinsichtlich Komplexität der tangierenden Technologien in schwindelerregende Höhen getrieben hat.
«SASE befindet sich aufgrund des übertriebenen Marketings vieler Technologieanbieter im Tiefpunkt der Ernüchterung.»
Quelle: Gartner, Hype Cycle for Zero Trust Networking (2023)
Immer mehr ZTNA-Lösungen ersetzen VPN-Ansätze
Unabhängig davon hat auch der Begriff Zero Trust Network Access (ZTNA) in den letzten Jahren an Bedeutung gewonnen. Sogenannte ZTNA-Lösungen ersetzen vermehrt traditionelle VPN-Lösungen für Anwendungszugriffe. Die Implementierung von Zero Trust Network Access bzw. die Wahl kann sich jedoch aus verschiedenen Gründen für viele Unternehmen nach wie vor als schwierig erweisen:
- Die CISO oder IT-Leiter wissen manchmal noch nicht, wo sie bei der Implementierung anfangen und Prioritäten setzen sollen.
- Die Kriterien zur Wahl eines qualifizierten Anbieters sind eventuell unübersichtlich.
- Oft existiert auch ein Mangel an internem Fachwissen.
- Darüber hinaus werden gegenwärtig neue Begriffe wie ZTNA 2.0 geprägt, die zusätzliche Verwirrung stiften.
Im Herbst letzten Jahres hat Gartner eine aufschlussreiche Marktanalyse zu den Zero Trust Network Access Trends durchgeführt. Die Studie gelangt zum Schluss, dass Organisationen vor allem bei VPN ihre Hauptmotivation bei der Bewertung von ZTNA-Angeboten priorisieren. Ein agentenbasiertes ZTNA wird zudem als Teil einer grösseren Secure-Access-Service-Edge-Architektur (SASE) oder Security-Service-Edge-Lösung (SSE) angesehen, um Always-on-VPNs zu ersetzen. Laut Gartner unterschätzen viele Organisationen allerdings noch den Zeit- und Arbeitsaufwand, der für die vollständige Bereitstellung von ZTNA erforderlich ist, um den Zugriff auf granulare Weise für alle Benutzer und Anwendungen zu isolieren. Als Folge davon dürften Unternehmen möglicherweise auch den daraus resultierenden Aufwand für die langfristige Wartung ihrer Systeme unterschätzen. Insgesamt, so Gartner, entwickle sich der ZTNA-Markt sehr schnell, während einige Anbieter auch von anderen verdrängt werden.
Was ist eigentlich ZTNA 2.0 und wie unterscheidet es sich von ZTNA 1.0?
Im Jahr 2022 gedeihte erstmals eine Idee namens ZTNA 2.0, welche ZTNA weiter verbessern soll. Viele werden sich fragen: Was ist denn nun eigentlich ZTNA 2.0? Wir haben ja noch nicht einmal mit ZTNA 1.0 beginnen können – wo sollen wir überhaupt beginnen?
Gemäss dieser Auslegung ging es bei ZTNA 1.0 rückblickend primär um die Beseitigung signifikanter VPN-Schwachstellen, da die Zugriffsberechtigung von Remote-Mitarbeitenden auf jede Ressource eines Unternehmensnetzwerks sich als ein sehr grosses Unternehmensrisiko erweisen kann. Aktuelle ZTNA-1.0-Ansätze (oder ältere Ansätze) sollen demnach einschliesslich rudimentärer Verhinderung von Datenverlust (DLP) gegenüber ZTNA 2.0 nur geringe oder keine erweiterte Sicherheit für alle Anwendungen ermöglichen, was sich über den Grundsatz des Least Privilege hinwegsetzen und Unternehmen einem erhöhten Risiko eines Verstosses aussetzen würde.
Least-Privilege-Berechtigung sollte sich dagegen noch viel präziser via Layer 7 steuern lassen. Sobald der Zugriff auf eine Anwendung gewährt werde, könne dadurch quasi das Vertrauen kontinuierlich anhand von Änderungen im Gerätestatus, aber auch im Benutzer- und App-Verhalten, bewertet werden. Nur so könne verdächtiges Verhalten festgestellt werden, um den Zugriff in Echtzeit widerrufen zu können.
«Zero Trust 2.0 ist nichts anderes als Marketing, das wirklich von einem Anbieter gesteuert wird», lässt sich Charlie Winckless, Senior Analyst bei Gartner, gegenüber dem Tech-Portal «Venture Beat» zitieren.
Es handele sich nicht wirklich um eine Weiterentwicklung der Technologie. Ein Grossteil der Formulierungen rund um ZTNA 2.0 ziele lediglich darauf ab, die Innovatoren in diesem Bereich und das, was ihre Produkte bereits böten, auf den neuesten Stand zu hieven. Nicht alle Funktionen würden von allen Kunden benötigt, und die Auswahl eines Anbieters sei mehr als nur ein falscher Marketingbegriff, so Winckless. Es sei quasi eine Version 2.0 für den Anbieter, nicht für die Technologie.
Fazit
Anwender sollten sich bewusst sein, dass ZTNA nur eine Komponente einer Zero-Trust-Strategie ist, wenn auch eine wichtige.
Eine ZTNA-Lösung erhöht gegenüber einem klassischen VPN die Sicherheit enorm, wenn zusätzlich mit Cloud- und webbasierten Anwendungen gearbeitet wird. Die Vorteile resultieren in einer besseren Sicherheit für Remote-Mitarbeitende, in einem sicheren Zugang zu Cloud-Diensten und Multi-Cloud-Umgebungen. Zudem werden sowohl das Zugriffsmanagement auf Anwendungsebene automatisiert und strenger geregelt als auch die Usability erheblich verbessert.
Gut konzipierte ZTNA-Dienste umfassen physische und geografische Redundanz mit mehreren Ein- und Ausstiegspunkten, um die Wahrscheinlichkeit von Ausfällen zu minimieren, welche die Gesamtverfügbarkeit beeinträchtigen. Darüber hinaus können die Service Level Agreements (SLA) der Anbieter (oder deren Fehlen) Aufschluss darüber geben, wie robust sie ihre Angebote einschätzen. Unternehmen sollten daher Gartner zufolge Integratoren mit starken SLAs bevorzugen, die Abhilfe bei Geschäftsunterbrechungen bieten.
Um mit der Flut an Neuerungen der einzelnen SASE- bzw. ZTNA-Anbieter Schritt halten zu können, lohnt es sich, ab und ein Webinar oder einen Round Table zu besuchen.
Weiterführende Links
Der Beitrag Was ist eigentlich ZTNA 2.0? erschien zuerst auf Tec-Bite.

Vulnerability Scans: Auf der Jagd nach digitalen Einfallstoren

Vulnerability Scanning, oder besser: Vulnerability Management sollte eigentlich standardmässig von allen Unternehmen regelmässig durchgeführt werden. Trotzdem treffe ich immer wieder auf Unternehmen, die gar nicht oder nur ungenügend nach Schwachstellen in ihrer Infrastruktur suchen. In diesem Beitrag möchte ich nach Gründen suchen und aufzeigen, wie man den Prozess schlank hält und effizient umsetzt.
Gründe für den Verzicht
Oftmals wird das automatisierte Patch-Management als Grund für den Verzicht aufgeführt. Die Server- und Client-Landschaften werden automatisiert in definierten Schritten gepatcht und auf den neusten Stand gebracht. Leider geht dabei vergessen, dass meist installierte Dritt-Applikationen (mit Ausnahmen) davon nicht betroffen sind. Es schlummern also immer noch versteckte Schwachstellen auf den Systemen. Diese können von einem Angreifer für den initialen Zugriff oder zur Ausweitung der Zugriffsrechte missbraucht werden. Abhilfe schafft hier nur ein komplettes Software-Inventar. Der schnellste Weg, dies zu erhalten, ist meist ein Vulnerability Scan. Zusätzlich tummeln sich im Netzwerk diverse Geräte, welche von diesem Patch-Management gar nicht betroffen sind.
Ein anderer viel genannter Grund ist die fehlende Zeit, dies umzusetzen. Dabei spielt oft auch die Angst mit, dass das Resultat des Scans wiederum zu Mehraufwand im Patching führt. Den Kopf in den Sand zu stecken, bringt aber meist nichts.
Was ich ebenfalls oft sehe, ist der Ansatz, dass ein Vulnerability Scan zwar durchgeführt wird, doch dann nur von extern gescannt wird. Meist auch nicht regelmässig, sondern nur periodisch. Das führt natürlich zu einem unzureichenden Bild und neue Schwachstellen werden erst beim nächsten Scan gefunden. Auch oft gesehen sind jährliche Scans von extern, oder auch von intern, um den entsprechenden Compliance Check zu erfüllen.
Welche Scan-Typen gibt es und wie sollte ich scannen?
Wie der Name schon vermuten lässt, handelt es sich um einen Scan von ausserhalb des eigenen Netzwerks. Klassischerweise wird aus dem Internet der eigene Perimeter gescannt, um öffentlich sichtbare Schwachstellen zu identifizieren. Anbieter wie tenable.io bieten dafür Cloud Scanner an, welche für das Scanning verwendet werden können, man muss also keine eigenen Scanner deployen. Der Scan sollte grundsätzlich täglich durchgeführt werden, damit Schwachstellen zeitnah detektiert und gepatcht werden können. Zudem bietet es sich an, zwei verschiedene Profile anzulegen. Einmal mit aktiverten Security Features (IPS) der Perimeter Firewall und einmal ohne. Der Vorteil dabei ist, dass Schwachstellen, für welche allfällige IPS Patterns existieren, trotzdem detektiert werden. Man weiss aber automatisch, dass diese aktuell nicht ausgenutzt werden können.
Interne Scans
Bei internen Scans wird das Netzwerk mit einem Scanner im eigenen Netz geprüft. Klassischerweise werden dafür eine oder mehrere virtuelle Maschinen deployt. Diese können in verschiedenen Security-Zonen installiert werden, damit das Zonen-Konzept eingehalten werden kann. Bei unauthentifzierten Scans werden die Assets rein aus dem Netzwerk gescannt. Sprich: Es werden nur Services und Applikationen getestet, welche aus dem Netzwerk ansprechbar sind. Bei authentifzierten Scans erhält der Schwachstellen-Scanner Zugriffsrechte auf das Asset und kann sich auf diesem einloggen. Damit können sowohl die Konfiguration als auch installierte Software auf Schwachstellen geprüft werden. Auch Best-Practice- und Hardening-Konfigurationen, wie z.B. CIS Benchmarks, können damit automatisiert geprüft und validiert werden.
Als Alternative zu netzwerkbasierten Scans können auch Agents auf den Zielsystemen installiert werden. Diese stehen für alle gängigen Betriebssysteme zur Verfügung und führen den Schwachstellen-Scan lokal auf dem Gerät aus. Dies bietet den Vorteil, dass man keine Credentials für den authentifzierten Scan zur Verfügung stellen muss. Zudem ist der Ansatz gerade bei Clients, welche sich oftmals ausserhalb des Netzwerkes befinden (Road Warrior), sinnvoll.
Interne Scans sollten, je nach Zone, bestenfalls täglich oder mindestens einmal wöchentlich durchgeführt werden.
Alerting und Reporting
Damit die Resultate der Scans nicht täglich manuell geprüft werden müssen, bietet sich ein automatisiertes Alerting und Reporting an. Neu gefundene Schwachstellen mit einer Kritikalität von «High» oder «Critical» sollten zur Triage weitergeleitet werden (E-Mail / Ticket / etc.). Zudem wird ein wöchentlicher oder monatlicher Report konfiguriert, welcher an einem definierten Wochentag versendet wird. In diesem werden nicht nur offene Schwachstellen aufgezeigt, sondern auch diverse Metriken wie z.B. Patching Performance. Für verschiedene Stakeholder können auch individuelle Report Templates verwendet werden.
Zusammenfassung
Vulnerability Management ist heute ein integraler Bestandteil jedes Security-Konzepts. Neben Phishing sind Schwachstellen das meist genutzte Einfallstor in Netzwerke. Leider gibt es noch diverse Unternehmen, welche aus verschiedenen Gründen auf ein Schwachstellen-Management verzichten.
Neben der Identifzierung von Schwachstellen können die Scanner auch Compliance Checks durchführen, um definierte Hardening- und Best-Practices-Konfiguration automatisiert zu validieren. Ein sinnvoll durchgeführtes Vulnerability Management kann die Sicherheit der Infrastruktur massiv erhöhen. Vieles davon kann automatisiert durchgeführt werden, führt also nicht zu viel Mehraufwand. Wer trotzdem keine Zeit dafür findet, kann das Ganze auch als Managed Service beziehen.
Der Beitrag Vulnerability Scans: Auf der Jagd nach digitalen Einfallstoren erschien zuerst auf Tec-Bite.

Go hack yourself! Bug Bounty vs. Pentesting

Wenn es darum geht, Schwachstellen in Anwendungen zu finden, bietet sich neben den klassischen Penetrationstests auch Bug Bounty an. Im Folgenden zeigen wir auf, warum sich die beiden Methoden zur Schwachstellensuche ergänzen und wie Sie vorgehen, um ein erfolgreiches Bug-Bounty-Programm zu starten.
Warum Bug Bounty?
Während bei klassischen Penetrationstests Anwendungen zu einem bestimmten Zeitpunkt auf Schwachstellen geprüft werden, ermöglichen Bug-Bounty-Programme eine kontinuierliche Überprüfung und ergänzen damit die bestehenden Sicherheitsmassnahmen. Das ist aber nicht der einzige Vorteil. Bug-Bounty-Jäger sind oft spezialisiert auf bestimmte und neuartige Schwachstellen, welche sie dann in verschiedenen Programmen suchen. Durch die Masse an Sicherheitsexperten, die in einem Bug-Bounty-Programm testen, ergibt sich eine breite und gleichzeitig tiefe Abdeckung der Schwachstellenprüfung, während bei Penetrationstests oft hauptsächlich mittels Checklisten in der Breite und nur punktuell in der Tiefe getestet wird.
Was ist denn jetzt besser?
Wenn man eine Schraube in einer Wand befestigen möchte, kann man zwar auch einen Hammer verwenden, besser wäre aber zweifellos ein Schraubendreher. Analog verhält es sich mit Bug Bounty und Penetrationstests. Die beiden Werkzeuge ergänzen sich. Während firmeninterne Systeme und Anwendungen und physische Systeme besser mittels Penetrationstests geprüft werden, entfalten Bug-Bounty-Programme die beste Wirkung bei öffentlich zugänglichen Anwendungen und Schnittstellen. Dank dem Crowd-Sourced-Ansatz erhöht ein Bug-Bounty-Programm zudem das Vertrauen in Ihr Unternehmen.
Aber Hacking ist doch strafbar?
Bug-Bounty-Jäger können nur unterstützen, wenn sie entsprechende Rechtssicherheit erhalten, denn Hacking ist strafbar. Selbst wenn sie sich aus Spass in den schlecht geschützten Mailaccount Ihres Nachbarn einloggen, indem sie das Passwort «1234» verwenden, machen sie sich bereits strafbar!
Deshalb beinhaltet der erste Schritt beim Aufbau eines Bug-Bounty-Programmes die Definition eines sogenannten Legal Safe Harbor, welcher die Spielregeln festlegt, unter deren Einhaltung auf rechtliche Schritte verzichtet werden.
- Welche Testmethoden sind erlaubt?
- Wie darf auf die Systeme zugegriffen werden?
- Wie muss mit gefundenen Schwachstellen und allfällig erlangten Kundendaten umgegangen werden?
- Welche Anwendungen sind im Scope und was ist auszuschliessen? Und vieles mehr.
Alle diese Fragestellungen sind bereits von den meisten Anbietern in einer Vorlage definiert, welche gemeinsam mit dem Kunden angepasst und ergänzt werden.
Wann lohnt sich ein Bug-Bounty-Programm?
Grundsätzlich können Sie jederzeit ein Bug-Bounty-Programm starten. Wichtig ist hierbei, dass Sie etappenweise einsteigen. Hier offerieren Bug-Bounty-Anbieter unterschiedliche Programmtypen die für den Reifegrad Ihres Vulnerability Managements und Ihrer Anwendung ausgelegt sind. Beispielsweise können unterschiedliche Zeitperioden, unterschiedliche Anzahl Bug-Bounty-Jäger etc. bestimmt werden.
Was braucht es noch für ein erfolgreiches Bug-Bounty-Programm?
Neben den Spielregeln muss genau festgelegt werden, was getestet werden soll. Welche Systeme und Schnittstellen? Wie hängen diese zusammen? Welche Technologien stecken dahinter? Ist der Scope definiert, folgt die Incentivierung der Bug-Bounty-Jäger durch das Festlegen der Bounties, welche für gefundene Schwachstellen ausbezahlt werden.
Um Überraschungen hinsichtlich Kosten vorzubeugen, wird ein Bounty-Budget festgelegt. Dies ermöglicht eine dynamische Anpassung des Bug-Bounty-Programms (Umfang, Dauer, Bounty-Prämien etc.). Die Höhe der Prämien wird in Anlehnung an markterprobte Prämien bestimmt. Je nach Sicherheitsniveau der zu testenden Anwendung können die Prämien höher oder tiefer bestimmt werden.
Danach kann das Bug-Bounty-Programm bereits gestartet werden. Dabei müssen die gemeldeten Schwachstellen auf deren Gültigkeit hin geprüft und triagiert werden. Für die gültigen Meldungen werden die vereinbarten Bounties ausbezahlt und allfällige Handlungsmassnahmen festgelegt.
Der Beitrag Go hack yourself! Bug Bounty vs. Pentesting erschien zuerst auf Tec-Bite.

Ein neuer kleiner Helfer auf dem Zscaler Client Connector

Ein neues Feature namens Zscaler Endpoint DLP optimiert den Schutz Ihrer Endgerätedaten. Aktuell werden externe entfernbare Datenträger wie USB-Sticks oder SD-Karten, Drucker, Netzlaufwerke und private Cloud Stores zur Kontrolle unterstützt. Eine einheitliche Richtlinie und ein einziger Agent verschaffen uneingeschränkte Einblicke in die Bewegungen sensibler Daten und beugen Datenverlusten durch die erwähnten Medien und auf anderen Wegen vor. Ein Beispiel einer Datei mit Kreditkartendaten soll einen kleinen Einblick in die Möglichkeiten zeigen.
Voraussetzung
Wir brauchen den ZCC (Zscaler Client Connector) 4.3.x und die Aktivschaltung des Features durch den Support. Voraussetzung ist eine Lizenz, in welcher der ZCC enthalten ist. Ein PoV (Proof of Value; also zuerst testen und dann kaufen) sollte aber sicher jederzeit für einen Monat möglich sein. Wenn das Feature aktiv ist, gibt es zwei Menüpunkte mehr:
- unter Administration – DLP Ressources, wo ich meine bekannten Devices und Cloudstores definieren kann, um eine Allow- oder Exception Rule zu bauen.
- unter Policy Endpoint Data Loss Prevention, wo ich meine DLP Rules pflege.
Funktionsweise von Zscaler Endpoint DLP
Zum Start dieses neuen Features kann das Ablegen von sensitiven Daten auf ein Netzlaufwerk eingeschränkt oder verhindert werden. Das gilt auch für den Cloudspeicher wie iCloud, OneDrive, Google Drive (Personal), Box (Personal), OneDrive oder den USB-Stick sowie das Ausdrucken!
Ich muss mir auch hier Gedanken machen, was denn bei uns sensitiv ist und eine entsprechende DLP Engine definieren, welche diese Daten klassifiziert:
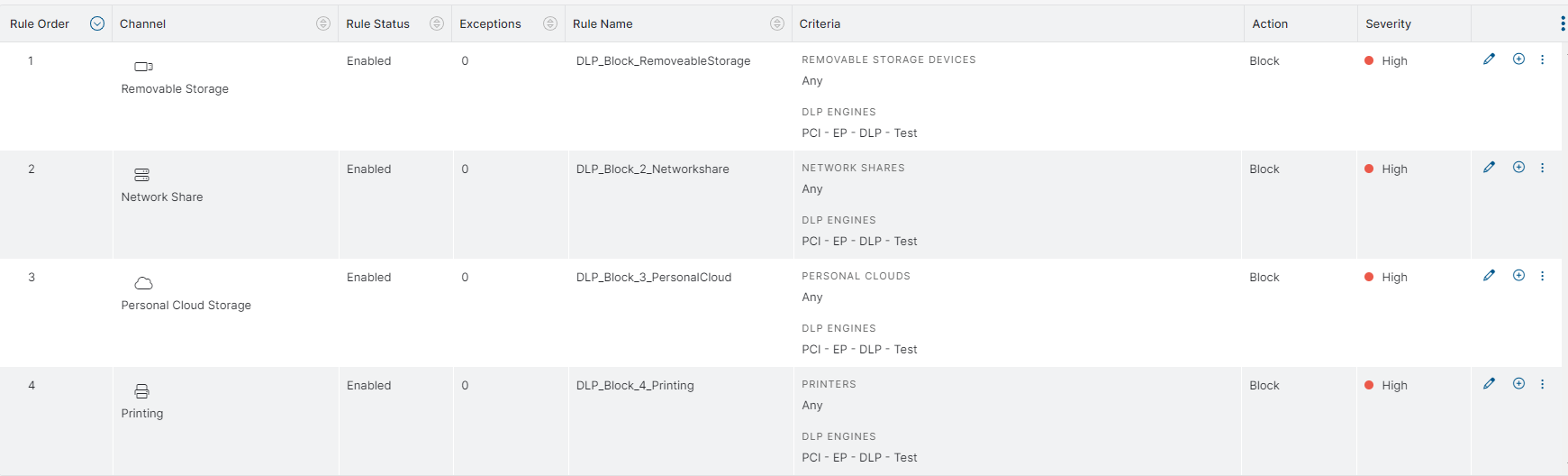
Wie sieht eine Policy aus?
Für unser Beispiel definiere ich eine DLP Engine aus der bestehenden PCI («PCI engine contains the Credit Cards and Social Security Number dictionaries») als Vorlage und limitiere auf einmal eine Kreditkartennummer oder US Social Security Number. Eines der beiden reicht für den Trigger. Den Inhalt habe ich per Google anhand von Beispielen bei Paypal entnommen und in eine Datei EPDLP-Test.txt abgelegt:
American Express
378282246310005
American Express
371449635398431
….
Mögliche Policy zum Start und Test:
Wie verhält es sich auf meinem MAC oder PC?
Wenn die Notification eingeschaltet ist, sieht man das Pop-up oben rechts. Das Speichern wird verhindert. Wir haben die Möglichkeit, einen Request für eine Ausnahme zu machen (Request Exception) oder dass wir nicht mehr damit gestört werden (Do Not Disturb), also nur noch weitere kritische Notifications angezeigt werden, aber diese nicht mehr.
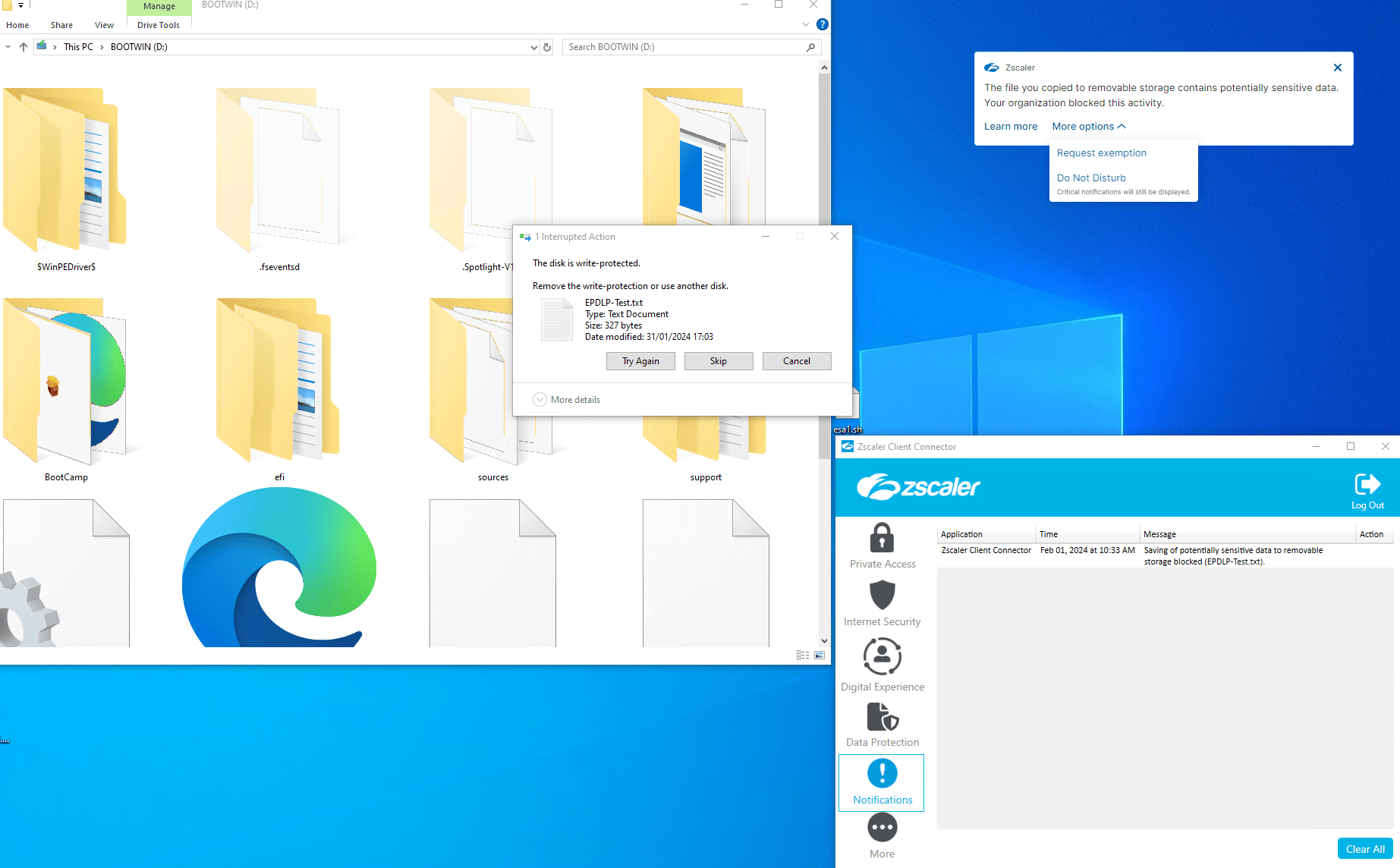
Per Drag and Drop wird versucht, das File EPDLP-Test.txt auf den USB-Speicher zu kopieren.
Da ich ebenfalls eine E-Mail-Adresse hinterlegt habe, erhalte ich eine Mail mit diesem Inhalt:
—cut—
The attached content triggered a Web DLP rule for your organization.
Transaction ID: 3522283109339254366
User Accessing the URL: alert@mail.address
URL Accessed:
Posting Type:
DLP MD5: 0aa3c1d7a0616a00ec4f696b2fd7d162
Triggered DLP Violation Engines (assigned to the hit rule):
|
Engine Name |
Expression |
| PCI – EP – DLP – Test | (((Credit Cards) > 1) OR ((Social Security Numbers (US)) > 1)) |
Triggered DLP Violation Dictionaries (assigned to the hit rule):
|
Dictionary Name |
Match Count |
| Credit Cards | 8 |
No action is required on your part.
—cut—
Unter Dashboard Endpoint DLP sehe ich:
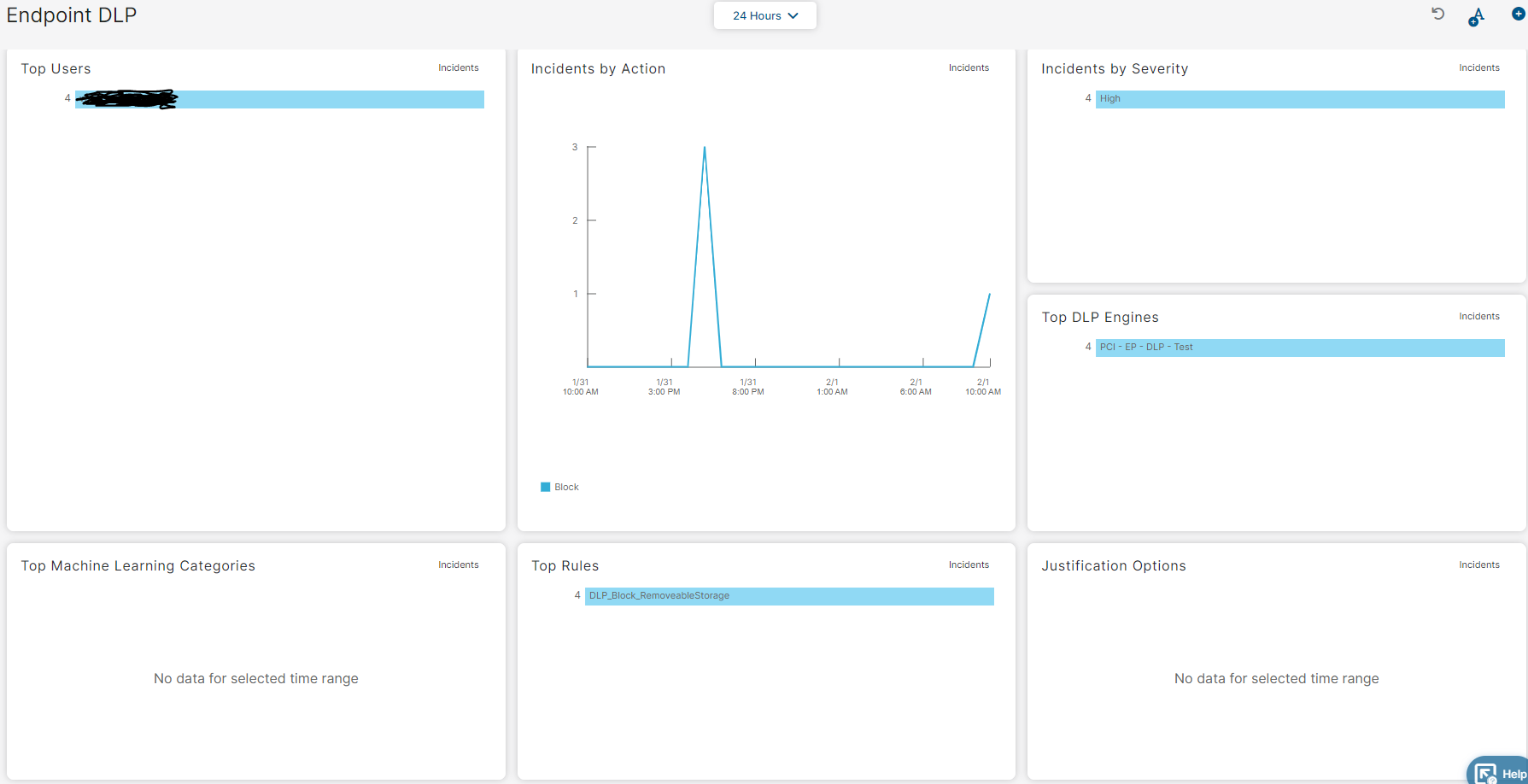
Natürlich gibt es auch Analytics Endpoint DLP Insights dazu. Dies ersparen wir uns jetzt.
Zusammenfassung
Es gibt noch diverse weitere Möglichkeiten wie ein Action «Confirm», bei welchem der User bestätigen muss, dass es nur seine persönlichen Daten betrifft. Wir können Alarme verschicken, wir können den NSS füttern uvm.
Dies würde den Rahmen des Blogs sprengen und kann unter den angegebenen Links weiterverfolgt werden:
help.zscaler.com/zia/about-endpoint-dlp
help.zscaler.com/zia/policies/endpoint-data-loss-prevention
Wenn auf diesen Blog viel Feedback eintrifft, doch das Ganze zu vertiefen, kann ich auch einen Teil II ausarbeiten.
Es ist der richtige Schritt von Zscaler, nun auch den Endpunkt zu bedienen und das mit der gleichen Software; nämlich dem Zscaler Client Connector. Es sei nochmals erwähnt, dass man seine Daten klassifiziert und entsprechende Engines definiert haben muss, damit dieses Feature auch erfolgreich verwendet werden kann.
Diese Erweiterung ist für mich eine Bereicherung und nach etwas Pröbeln und Lesen der Onlinehilfe bei Zscaler kommt man schnell zu einem Erfolgserlebnis. Es ergibt viel Sinn, dass man das Ausdrucken von sensitiven Dokumenten im Office steuern kann. Auch das sorglose Kopieren von sensitiven Daten auf beliebige Datenträger oder gar in persönliche Cloudaccounts wird gesteuert. Eine sehr sinnvolle Erweiterung aus meiner Sicht und ich kann nur empfehlen, sich einmal ein paar Gedanken über die eigene Situation in der Firma zu machen.
Der Beitrag Ein neuer kleiner Helfer auf dem Zscaler Client Connector erschien zuerst auf Tec-Bite.

Die Grenzen von Detection und Response

Viele Organisationen setzen heutzutage auf Detection-and-Response-Technologien wie Network Detection and Response (NDR) oder Endpoint Detection and Response (EDR), die effektive Automatisierung wie KI und maschinelles Lernen (ML) beinhalten. Solche Technologien einzusetzen, erhöhen den Schutzlevel schon auf ein gutes Niveau. Leider können damit aber nur ca. 80 bis 90 Prozent der Cyber-Angriffe eindeutig identifiziert werden.
Automatische Responses (zum Beispiel Endpoint Containment) helfen bei den meisten Detections. Jedoch bleibt immer ein kleiner Rest an Detections übrig, bei denen nicht eindeutig klar ist, ob es sich um ein True oder False Positive handelt. In Fällen solch unklarer Erkennungen könnte eine automatische Blockierung möglicherweise zu einem erheblichen Business Impact führen.
Zero Trust beinhaltet folgende zwei Denkweisen:
Assume a breach! Gehen Sie davon aus, dass Ihre Organisation jederzeit angegriffen werden kann. Auch gerade jetzt. Es gibt keinen 100-prozentigen Schutz!
You are under Attack! Gehen Sie davon aus, dass nicht alle Sicherheitsvorgaben eingehalten wurden und dass die «Angreifer» bereits in Ihrem Netzwerk sind, resp. sich bereits auf Ihren Systemen eingenistet haben.
Eine moderne Cyber-Abwehr sollte beide Aspekte gebührend berücksichtigen.
Business Impacts infolge unklarer Blockierungen
Ein weiterer bedeutender Aspekt ist der Mangel an geschulten und spezialisierten Mitarbeitenden für Cyber Defense, die sich um diese Technologien (NDR/EDR) kümmern. Insbesondere kleinere und mittelständische Unternehmen haben oft Schwierigkeiten, qualifiziertes Personal zu finden, und wenn sie es doch tun, wechseln diese nach ein paar Jahren möglicherweise aus Langeweile den Job. Zudem fehlt bei kleinen und mittelständischen Unternehmen auch die Zeit, sich um solche modernen Angriffe zu kümmern.
Hinzu kommt, dass selbst die besten Produkte zur Erkennung und Reaktion nie alle Cyber-Vorfälle detektieren können. Es ist auch ein Irrglaube anzunehmen, dass mehr Technologie weniger Bedarf an Bedrohungsanalysten mit sich bringt.
Zusätzlich zu den durch die Technologie gefundenen Erkennungen gehört auch das fortlaufende manuelle Suchen nach möglichen Bedrohungen (Threat Hunting). Threat Hunting ist wichtig, da komplexe Bedrohungen in der Lage sind, Erkennungs- und Reaktionstechnologien zu umgehen. Gerade bei den durch das Threat Hunting aufgedeckten Bedrohungen handelt es sich häufig um hochkomplexe Angriffe, die erheblichen Schaden anrichten können.
Unentdeckte Bedrohungen richten immer den grössten Schaden an
Eine effiziente Cyber-Abwehr benötigt beides – einerseits fortschrittliche Erkennungs- und Reaktionstechnologien. Andererseits als Ergänzung das Know-how und die Erfahrung der Threat-Analysten und Threat Hunters, die wie der Angreifer denken und handeln.
Es ist ebenso wichtig, dass die Bedrohungen nicht nur während Bürozeiten gesucht, analysiert und bewertet werden und ggf. darauf reagiert wird (Playbooks), sondern dass dies rund um die Uhr geschieht. Angreifer sind nicht unbedarft und nutzen für ihre Angriffe das optimale Zeitfenster aus, welches ihnen möglichst viel Zeit verschafft, um so unentdeckt einen grösstmöglichen Schaden anzurichten. Diese Zeitfenster liegen meistens nach den Bürozeiten, an Wochenenden oder innerhalb der Feiertage.
Dies kann entweder durch ein internes Security Operation Center (SOC) oder durch einen externen Managed Detection and Response (MDR) Service realisiert werden. Gerade für kleinere und mittelständische Unternehmen ist es finanziell attraktiver, einen MDR-Service von einem professionellen SOC-Anbieter zu erwerben, da ein 24/7-Betrieb mindestens sechs bis sieben Experten erfordert und diese Analysten kontinuierlich in Cyber-Abwehr geschult werden müssen, um den Angreifern einen Schritt voraus zu sein.
Fazit
Vertrauen Sie nicht nur auf Technologie! Der menschliche Faktor ist nach wie vor ein wichtiger Baustein in der Cyber-Abwehr, auch wenn immer mehr KI und ML in den Detection-Technologien vorzufinden ist. Cyber-Defence-Experten verstehen das Denken der Angreifer.
Etablieren Sie ein professionelles 24/7 SOC und schulen Sie die Experten stetig auf Cyber-Abwehr und Threat Hunting oder weichen Sie auf einen professionellen MDR-Service-Anbieter aus, der diese herausfordernde Arbeit für Sie übernimmt. Ein MDR-Service-Anbieter kann einen reellen Mehrwert schaffen – diesen betreuen viele Kunden und er kann wichtige Erkenntnisse von anderen Organisationen auch in Ihre Cyber-Abwehr einfliessen lassen.
Weiterführende Links:
www.avantec.ch/services/managed-detection-and-response-service
www.tec-bite.ch/braucht-jedes-unternehmen-ein-soc
www.tec-bite.ch/welches-soc-passt-intern-extern-hybrid-passende-soc
www.tec-bite.ch/welche-moeglichkeiten-gibt-es-fuer-detection-response
www.tec-bite.ch/managed-threat-hunting-was-bringt-das
www.tec-bite.ch/endpoint-detection-and-response-wer-richtig-sucht-der-findet
Der Beitrag Die Grenzen von Detection und Response erschien zuerst auf Tec-Bite.

Tuning-Tipp: HyperFlow und Dynamic Balancing von Check Point

Bekanntlich ist es in der Nacht effizienter, grosse File Transfers wie ISO-Abbilder von virtuellen Betriebssystemen oder sehr grosse Downloads zu managen. Um solche Terabytes an Daten in Minuten statt Stunden sicher zu übertragen, müssten die Firewalls jedoch praktisch zu jederzeit ihre CPU-Core-Zuweisungen automatisch ändern können. Ein neues Feature namens «HyperFlow» von Check Point auf den Security Gateways R81.20 ist nun in der Lage, grosse TCP-Netzwerk-Links auf mehr als einem CPU-Kern parallel verarbeiten zu können. Zudem verteilt die Funktion die gesamte Inspektionsaufgabe in kleineren Aufgaben an die verfügbaren Kerne. Was ist von dieser Neuerung zu halten?
Ein Beispiel, das man bei Firewalls schon kennt, ist Dynamic Balancing. Die Funktion verteilt den Netzwerkverkehr intelligent auf verschiedene Firewall-Instanzen. Bei praktisch null Traffic-Verlust sind dazu keine manuelle Konfiguration und keine Reboots nötig. Bei sehr grossen TCP Flows geraten Firewalls, beispielsweise bei nur einem aktiven Core, jedoch meist an ein Limit beim Durchsatz.
Sehr grosse TCP-Datenströme schneller inspizieren
Sogenannte «Elephant Flows» bestehen in der Regel aus einer Vielzahl von Bytes und TCP- bzw. UDP-Verbindungen. Es handelt sich meist um eine Netzwerk-Session bzw. einen sehr grossen Flow über einen Netzwerk-Link. Ein typisches Beispiel ist ein sehr grosses File wie eine ISO-Datei eines Linux-Betriebssystems, welches via http, https, FTP oder NFS durchgeschleust wird. Diese Daten beanspruchen meist deutlich mehr Netzwerk-Kapazität im Vergleich zu anderen Datentransfers. Vor der Version 81.20 würde eine Firewall dazu nur einen Core beanspruchen können, um den Elephant Flow zu inspizieren. Darüber hinaus nimmt der Datendurchsatz allmählich ab, wenn die CPU-Auslastung auf dem Security Gateway zunimmt.
Dadurch benötigt das Security Gateway weniger Zeit bei der Überprüfung grosser Datenströme. Die CPU-Kerne werden automatisch erkannt und dynamisch den Hauptaufgaben eines Security Gateways zugewiesen. Die Reaktionszeit der CoreXL-Firewalls wird dadurch verbessert.
Standardmässig ist die HyperFlow-Funktion bei den Check Point Appliances aktiviert, welche die Systemanforderungen erfüllen. Das Feature wird jedoch nur dann aktiviert, wenn es benötigt wird und die gesamte CPU-Auslastung dies zulässt. Allgemein arbeitet HyperFlow im Standby-Modus und wird ausgelöst, wenn ein sehr hoher Workload erkannt wird. Das heisst: Die Funktion schaltet sich erst dann wieder in den Passiv-Modus, wenn der grosse Datendurchsatz auf den Firewalls stattgefunden hat.
Ab wann ist HyperFlow verfügbar?
HyperFlow ist bei den Check Point Firewalls ab der Version R81.20+ verfügbar.
Fazit
Besonders in grossen Netzwerken dominieren Elephant Flows. Diese können über einen bestimmten Zeitraum einen unverhältnismässigen Anteil der gesamten Bandbreite bei den Security Gateways von Firewalls einnehmen. Das Feature HyperFlow von Check Point ist mit Sicherheit eine gute Ergänzung und ergibt Sinn bei sehr hohen Datendurchsätzen. Der gesamte Durchsatz bei Firewalls hat jedoch immer Priorität gegenüber sogenannten Elephant Flows.
Weiterführende Links
Der Beitrag Tuning-Tipp: HyperFlow und Dynamic Balancing von Check Point erschien zuerst auf Tec-Bite.

Aufbau und Ausbildung eines Cyber Crisis Management Teams

Können wir uns mittels gezielten Trainings auf zukünftige Cyber-Security-Vorfälle vorbereiten, sodass wir im Ernstfall möglichst keine Zeit verlieren und die richtigen Entscheide treffen? Diesen Fragen sind wir im Blogbeitrag vom 23. August 2023 nachgegangen. Im ersten Teil der Blogserie wurde über das Trainieren von Cyber-Security-Vorfällen aufgezeigt, warum Trainings unerlässlich sind, welche Voraussetzungen diese benötigen, welche Varianten von Trainings existieren und welche Rollen explizit trainiert werden sollen. Im zweiten Teil der Serie möchten wir der Frage nachgehen, weshalb man ein Cyber Crisis Management Team benötigt und wie ein solches Team aufgebaut, ausgebildet und trainiert wird.
Warum benötigen wir ein Cyber Crisis Management Team
Im ersten Blogbeitrag dieser Blogserie wurde erwähnt, dass für den Incident-Response-Prozess ein Major Security Incident Management bzw. ein Cyber Crisis Management Team (dieser Begriff wird nachfolgend verwendet) benötigt wird. In einem ersten Schritt wollen wir der Frage nachgehen, wieso es überhaupt ein solches Team erforderlich ist.
Cyber Security Incidents werden in der Regel in zwei Kategorien eingeteilt: in «Minor Security Incidents» (kleinere Sicherheitsvorfälle) und «Major Security Incidents» (schwerwiegende Sicherheitsvorfälle). Im ersten Fall sind nur einzelne Hosts betroffen und es entsteht kein signifikanter Schaden (kein finanzieller Schaden, kein Datenabfluss, keine Reputationsschäden, keine Verletzung von Gesetzen). In so einem Falle arbeitet das Incident Response Team den Sicherheitsvorfall ab und informiert die Sicherheitsverantwortlichen. Im zweiten Fall müssen aber schwerwiegende Entscheidungen gefällt werden, welche die Kompetenzen das Incident Response Teams übersteigen. Dennoch will man aber nicht gleich eine unternehmensweite Krise ausrufen und den Krisenstab aufbieten. Hier ist einen Zwischenebene hilfreich. Diese Zwischenebene bildet das Cyber Crisis Management Team.
Aufgaben des Cyber Crisis Management Teams
Im Falle eines Major Security Incidents müssen sehr schnell wichtige Entscheidungen getroffen werden, unter anderem:
- Verfügen über weitreichende Containment-Massnahmen
- Einfordern ausserordentlicher Bereitschaft für Betreiber betroffener Systeme / Applikationen (IT SCM)
- Anordnen von Business-Continuity-Massnahmen für betroffene Systeme / Dienste / Applikationen (BCM)
- Involvierung des Versicherungspartners
- Abstimmung mit der Kommunikationsabteilung für die Kommunikation nach innen und aussen
- Bestimmung über Involvierung der Polizei/Strafverfolgungsbehörden
- Meldung einer Datenschutzverletzung an nationale Behörden
- Beauftragung einer Auswirkungs-Analyse über alle Geschäftsbereiche
Die obigen Aktivitäten sind nicht abschliessend aufgelistet und je nach Organisation müssen weitere spezifische Aktivitäten erfasst werden. Die Länge der Liste zeigt aber auf, dass ein strukturierter Ansatz gewählt werden muss und Verantwortliche gezielt geschult werden müssen.
Aufbau des Cyber Crisis Management Team
Anhand der oben aufgelisteten Aktivitäten ist ersichtlich, dass in der Regel Personen aus dem Senior Management der verschiedenen Geschäftsbereiche benötigt werden. In der Regel sind mindestens folgende Rollen Mitglieder des Cyber Crisis Management Teams:
- Leiter IT / IT Operations
- CISO (Chief Information Security Officier)
- Business-Bereichsleiter (nur falls IT-Systeme betroffen sind)
Je nach Umfeld können aber weitere Rollen integriert werden:
- Key Account Manager der IT-Provider
- Standortleiter der betroffenen Standorte
- IT-Risiko Manager
In der Regel existiert dieses Team nicht und muss zuerst organisatorisch geschaffen werden.
Ausarbeitung des Cyber Crisis Management Prozess und Checkliste
In einem nächsten Schritt wird der Cyber-Crisis-Management-Prozess ausgearbeitet. In der Regel ist dies ein simpler Prozess, welcher Iterative aus Abhalten von Lagebesprechungen sowie der kontinuierlichen Koordination der Aktivitäten beruht. Die Lagebesprechung selbst basiert auf einer Checkliste, welche bei jeder neuen Lagebesprechung abgearbeitet wird.
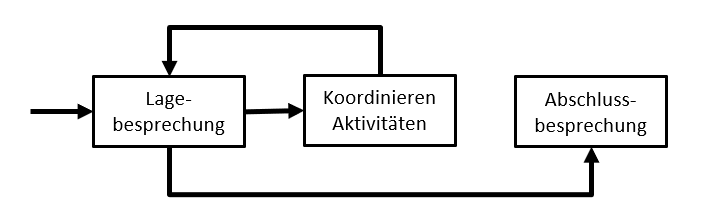
Abbildung 1: Beispiel – ein einfacher Prozess für Cyber Crisis Management
Onboarding des Cyber Crisis Management Teams mittels Process Walkthrough
Nun ist es an der Zeit, das Cyber Crisis Management Team zu aktivieren. Dazu wird im Idealfall ein Onboarding Workshop durchgeführt. Im ersten Teil wird ein Hintergrund über Cyber Security Incidents geben und nachfolgende Fragen werden erläutert:
- Worin unterscheiden sich ein Event, ein Alert oder ein Incident?
- Wie werden Alerts detektiert?
- Wer triagiert Alerts?
- Welche Massnahmen werden eingeleitet?
Alle Aspekte sind natürlich im Incident-Response-Prozess abgebildet. Dieser Prozess wird dem Cyber Crisis Management Team erläutert und das Team wird über seine Aufgaben, Kompetenzen und Verantwortlichkeiten informiert.
Im dritten Teil des Workshops (Prozess-Walk-Through) wird anhand eines beispielhaften Cyber Security Incidents (z.B. einer erfolgreichen Ransomware-Attacke) der Prozess Schritt für Schritt durchlaufen. Vom Eintreffen des ersten Alarms, über die Ausrufung der Cyber-Krisen bis hin zur Abarbeitung der Checkliste während der Lagebesprechung werden alle Aktivitäten der unterschiedlichen Rollen illustriert. Zum Abschluss des Workshops werden Inputs und Feedbacks der Mitglieder entgegengenommen und der Prozess sowie die Checkliste werden entsprechend angepasst.
Durchführen einer ersten Tabletop-Übung
Nun ist man bereit, die erste Tabletop-Übung durchzuführen. Das Ziel dieser ersten Übung ist es, die Grundlagen zu testen:
- Funktioniert die Einberufung des Cyber Crisis Management (z.B. automatisierter Rundruf)?
- Kennen die Mitglieder des Cyber Crisis Management Teams den Prozess?
- Finden die Mitglieder die Checkliste auf der Dateiablage? Wissen sie, wo das Dokument offline verfügbar ist?
- Ist man in der Lage, ein Protokoll zu erstellen?
- Werden die resultierenden Aufgaben ausgewogen auf die verschiedenen Mitglieder verteilt?
Aus diesen Zielen ist ersichtlich, dass das erste Tabletop-Scenario nur bedingt an die Organisation angepasst werden muss und ein sehr rudimentäres Szenario verwendet werden kann. Nach der Tabletop-Übung wird eine Nachbesprechung durchgeführt. Dabei werden gemeinsam Schwachstellen identifiziert und Verbesserungsmassnahmen adressiert.
Fazit – Krisenfähigkeit durch periodische Trainings erlangen
Es gibt verschiedene Massnahmen, um die Cyber Resilience zu erhöhen. Eine dieser Massnahmen ist der Aufbau eines Cyber Crisis Management Teams. Das Team übernimmt dann bei einem Major Security Incident den Lead und soll ein gut funktionierendes Krisen-Management garantieren. Der Aufbau eines solchen Teams kann mit relativ wenig Aufwand umgesetzt werden. Man muss einen simplen Prozess entwerfen, eine initiale Checkliste erstellen und Personen des Senior Managements dem Team zuweisen. Danach müssen die Personen mittels Onboarding über ihre Pflichten informiert werden. In der Praxis bringt dies aber erst dann einen Nutzen, wenn das Cyber Crisis Management Team periodisch (mindestens einmal im Jahr) mittels Tabletop-Übung trainiert wird. Krisenfähigkeit kann nur durch regelmässiges Training erlangt werden.
Weiterführende Links
Der Beitrag Aufbau und Ausbildung eines Cyber Crisis Management Teams erschien zuerst auf Tec-Bite.