
Hier nun endlich noch die Ergänzung zum SAML Artikel. Wir wollen hier den Ball aufnehmen und uns kurz erinnern: Die Authentisierung via SAML ist konfiguriert, funktioniert und im SAML Assertion (Token / Claim) stehen nur die wichtigen und notwendigen Informationen.
Wie bei einem guten Einlass wurde unsere Identität durch den Pförtner geprüft, die «ID» wurde verifiziert, und wir erhalten unseren Besucher-Badge, der nur für die relevanten Bereiche gültig ist.
Im «Badge» oder SAML-Token stehen nur wichtige Informationen:
- Success (Pfeil 2 im SAML Artikel, siehe Abbildung rechts)
- NameID (Pfeil 3, siehe Abbildung rechts)
- Und eventuell Gruppen (Pfeil 6, siehe Abbildung rechts) oder Attribute, die wir dann für den Zugriff brauchen
- Im realen Leben vielleicht noch ein Foto (Sichtausweis)

Wenn unser Service Provider nun diese Daten im SAML Provisioning verwendet und dann für die Zuweisung der Ressourcen oder Zugriffsberechtigungen nutzt, ist doch alles gelaufen – oder?
Warum dann noch SCIM?
Nun, wenn man ein Policy Management aufbauen will, müssen wir zum Beispiel die Gruppeninformation irgendwoher vorab lernen. Also bauen wir eine LDAP Connection auf und ziehen diese Information. Gerade im Cloud-Kontext wollen wir, wie bei SAML, aber diesen Zugriff auf unsere Directory Services nicht erlauben. Ein Push von unserer Umgebung zu den Cloud-Instanzen wäre hier schon viel schöner. Am besten wollen wir auch genau steuern, welche LDAP-Attribute wir überhaupt rausgeben und eventuell noch welches Attribut auf welches Attribut oder Datenbankfeld in der Cloud synchronisiert wird. Dann muss der Hersteller so einen Agenten bauen und liefern. Was viele Hersteller auch einige Jahre gemacht haben und irgendwann kommt man bei dieser n:m Beziehung dahinter, dass ein gemeinsamer Standard helfen könnte. Voila: Directory Synchronisation via http – wie es sich für die Cloud gehört.
Für unseren Anwendungsfall mit der SAML Authentication lernen, aktualisieren oder löschen wir die Gruppen.
Wie das im Azure Active Directory genau funktioniert, sieht man hier: docs.microsoft.com/en-us/azure/active-directory/app-provisioning/use-scim-to-provision-users-and-groups.
Kann das noch mehr?
System for Cross-domain Identity Management (SCIM) ist nun dieser Standard, der für den Abgleich der Informationen aus dem IdP zu verschiedenen anderen Verzeichnisdiensten oder Datenbanken die Informationen abgleichen soll. Früher hat man dafür MetaDirectory Services verwendet. Ach, die guten alten Z…
SCIM ist explizit für die Verwaltung der Benutzerinformation in cloud-based Applications erschaffen worden. Dafür braucht es in diesen heterogenen Umgebungen einiges an Definitionen, die in den RFCs festgehalten sind. Siehe unten.
Es regelt, was und wie etwas übertragen werden soll. Scope, Attributes, Struktur (Json / xml) und über welche Kommunikationswege, was erlaubt ist (create, update, delete). Wie im Bild zu sehen ist, wird genau definiert, welche Informationen übertragen werden und wie die Inhalte in den verschiedenen Datenbanken oder Verzeichnissen der unterschiedlichen SaaS –Applikationen zu mappen sind.
Es ist natürlich http-based und sinnvollerweise verschlüsselt, also https. Die Authentisierung (OAuth2) wie so oft via API Key und Bearer-Token.
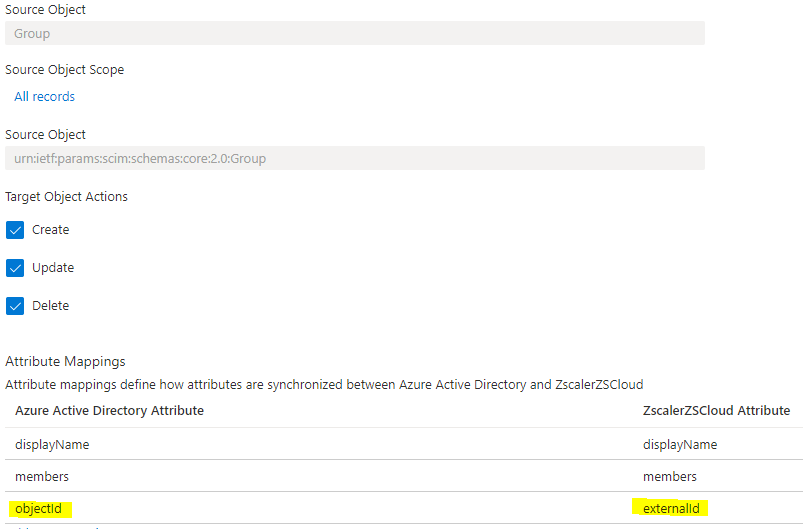
Quelle: Aus unserer eigenen Test-Konfiguration, abgerufen am 14.10.21
Der grosse Vorteil gegenüber reinem SAML Provisioning ist also, dass mit SCIM regelmässige Updates vom Directory Service zum Service Provider erreicht werden, auch wenn sich die Benutzer nicht anmelden und damit ist dann auch ein Clean-Up gegeben und Benutzer Informationen werden auf der Service Provider Seite wieder gelöscht.
Alternative
Vor allem als Fallback gibt es dann immer noch ein LDAP Lookup für on premise Umgebungen, um die notwendigen Informationen zu ziehen oder wie vorab angesprochen, spezifische Agents der Hersteller, um Directory Services Informationen in die Cloud zu pushen. Natürlich nur die Daten, die uns nicht weh tun und Password Hashes sind, denn das ist aus meiner Sicht, ein generelles No Go.
Der Beitrag System for Cross-domain Identity Management (SCIM) erschien zuerst auf Tec-Bite.