
In meinem vorherigen Artikel zu EDR habe ich mich mit dem Suchen und Finden auseinandergesetzt – dem Detection Teil (Endpoint Detection and Response – wer (richtig) sucht, der findet!). In diesem Teil möchte ich mich nun auf darauf konzentrieren, was passiert wenn man etwas gefunden hat: die Response.
So hat Response früher ausgesehen
Als ich in der IT anfing bestand die «Response» bei einem Vorfall meistens darin, den befallenen Rechner einfach neu aufzusetzen. Mit Ursachenforschung, geschweige denn weiterführender Spurensuchen im restlichen Netzwerk, hat man sich kaum auseinandergesetzt. Was auch gut dazu geeignet war, den Lehrling für ein paar Stunden zu beschäftigen. Dazu muss man auch sagen, dass vor 20 Jahren die Bedrohungslage noch etwas anders aussah als heute. Es gab wohl schon Viren und Würmer, die man sich beispielsweise auf NSFW-Websites einfangen konnte, trotz NSFW war das leider auch im Office ein Thema, denn Web Proxies mit URL Filter wurden noch nicht genutzt. Aber so richtig clevere, zielgerichtete Attacken wie man sie heute sieht, waren für die allermeisten Unternehmen kein Thema. Antivirus schlägt Alarm → Maschine wird frisch aufgesetzt → Problem gelöst.
So kann Response heute bei einem EDR-System aussehen
Ein EDR-System wie beispielsweise das von CrowdStrike bietet für den Response Teil verschiedene Möglichkeiten. So lässt sich ein betroffenes System ohne viel Aufwand vom restlichen Netzwerk isolieren. Ein isoliertes Gerät darf dann nur noch mit der Cloud von CrowdStrike kommunizieren, alles andere wird konsequent unterbunden. Somit wird verhindert, dass sich eine Malware oder ein Angreifer weiter ausbreitet. Aber wie kann ich die Bedrohung beseitigen? Dafür gibt es die Real Time Response, eine Art Reverse Shell, die den Fernzugriff auf das betroffene Gerät erlaubt, auch wenn dieses isoliert ist.
In dieser Shell kann der Responder nun beispielsweise bösartige Files löschen, Prozesse abschiessen, modifizierte RegKeys bereinigen, eigene vorgefertigte Scripts benutzen oder den Rechner herunterfahren oder neustarten. Die Shell stellt somit ein sehr mächtiges Werkzeug zur Verfügung, das natürlich auch Potenzial zu Missbrauch bietet. Um dem entgegenzuwirken, kann über eine anpassbare Response Policy genau definiert werden, wer was darf und was nicht. Zudem wird über ein Rollen Modell gesteuert, welcher Benutzer welche Tätigkeiten übernehmen darf. Zusätzlich wird auch jeder Einsatz der Real Time Response genau protokoliert, so dass man für Audit Zwecke immer detailliert sehen kann, wer auf welchem System zu welcher Zeit welche Commands ausgeführt hat.
Das Incident Response Framework
Wesentlich umfangreicher ist jedoch das Thema Incident Response. Wenn man sich mit Incident Response etwas vertieft befasst, merkt man recht schnell, dass es mit Neuaufsetzen eben nicht getan ist. Sowohl NIST wie auch SANS bieten ein Incident Response Framework, jeweils mit 4 rsp. 6 Schritten:
NIST
- Preparation
- Detection and Analysis
- Containment, Eradication & Recovery
- Post-Incident Activity
SANS
- Preparation
- Identification
- Containment
- Eradication
- Recovery
- Lessons learned
Beide Frameworks sind im Grunde gleich, unterscheiden sich nur insofern, dass bei NIST im Punkt 3 die Themen zusammengefasst werden, wohingegen das SANS Framework diese Themen einzeln behandelt.
Der Einfachheit halber verwende ich als Grundlage das NIST Framework.
Link zum NIST «Computer Security Incident Handling Guide”: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf
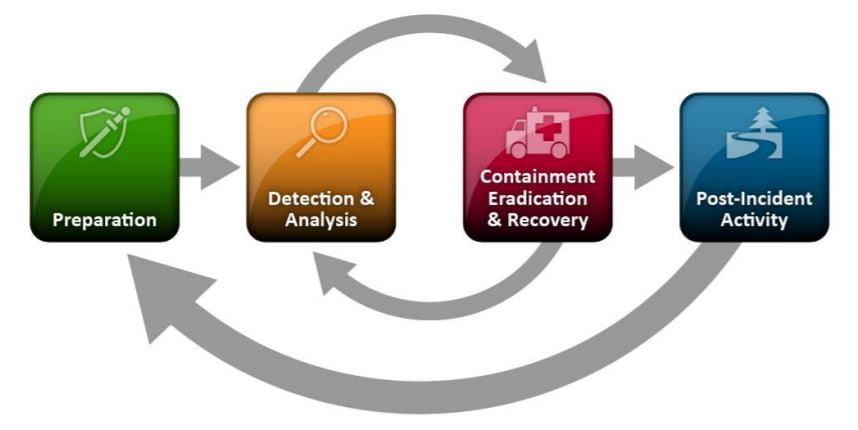
Quelle: NIST Incident Response Life Cycle; https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf; S. 21; abgerufen am 8.7.2020
Schritt 1: Preparation
Ganz im Sinne des Sprichworts «Erhoffe das Beste, sei gefasst auf das Schlimmste» ist eine gute Vorbereitung das A und O. Man soll sich nicht fragen, ob es einen Data Breach geben wird, sondern wann. Wenn man sich nämlich unter dem Druck eines kritischen Vorfalls zuerst noch einen Plan aus den Fingern saugen muss, ist das eher nicht so toll.
Mitunter gehören zur Vorbereitung Punkte wie:
- Kontaktinformationen: von internen Mitarbeitern sowie von externen Partnern und Anlaufstellen.
- Verschiedene Kommunikationskanäle: bei einem Incident ist die interne Telefonanlage womöglich nicht verfügbar – Alternativen müssen her.
- Issue Tracking System: um festzuhalten was für Probleme auftreten und welche Schritte unternommen wurden.
- Containment Strategy: Ausarbeitung einer Eindämmungstrategie basierend auf Art und Schweregrad des Angriffs.
- Sichere Aufbewahrungsmöglichkeit für Beweissicherung: bei einem fortlaufenden Vorfall muss sichergestellt werden, dass die Beweise nicht zerstört werden können.
- Software / Hardware für Spurensicherung: Packet Sniffer, weiterführende Forensiksoftware, um Disk Images und Memorydumps analysieren zu können, EDR / NDR Systeme.
- Dokumentation der Umgebung: eingesetzte OS Versionen, Applikationen, Security Produkte.
- Netzwerkdiagramm
- Liste kritischer Systeme: welche Systeme müssen priorisiert behandelt werden? Ein ERP dürfte wichtiger sein als eine kollektive Musiksammlung im IT Share, es sei denn es hat echt guten Sound drauf

- Zugang zu sauberen Images und Backups: für System Restores. Stichwort offline Backups. Das gute alte Tape im Banktresor ist in so einem Fall sein Gewicht in Gold wert.

Dabei umfasst die Vorbereitung nicht nur eine adequate Reaktion auf einen Vorfall, sondern sollte auch dessen Vermeidung berücksichtigen, indem sichergestellt wird, dass Systeme, Netzwerke und Applikationen ausreichend geschützt sind. Das beinhaltet:
- Risk Assessment: Systeme sollten regelmässig auf ihre Verwundbarkeit geprüft werden. Kritische Systeme wie beispielsweise exponierte Webserver oder wichtige Datenbanken sollten priorisiert behandelt werden.
- Host Security: Sämtliche Server und Rechner im Netz sollten gehärtet werden. Dazu bietet Windows viele Konfigurationsmöglichkeiten, die über GPOs zentral verwaltet werden können. Zudem sollte mit dem Least Privilege Prinzip gearbeitet werden. Lokale Admin Rechte sind ein Jackpot für jeden Angreifer. Ein Kollege hat dazu einen lesenswerten Artikel verfasst: Least Privileges – ein Traum nicht nur für Träumer.
- Network Security: Umfasst sowohl Firewalls, Proxies und VPN. Aber auch Themen wie Network Discovery and Response und Netzwerksegmentierung.
- Malware Prevention: das schwächste Glied in der Kette ist und bleibt der Endpoint. Gerade mobile Mitarbeiter mit Laptops werden nicht durch herkömliche Perimeter Security Lösungen geschützt, die Rechner sollten also umbedingt entsprechend berücksichtigt werden.
- User Awareness: ist an und für sich eine gute Sache, wenn nicht regelmässig wiederholt und geprüft aber Perlen vor die Säue (etwas überspitzt vielleicht). Ich persönlich vertraue lieber auf solide technische Lösungen als auf die menschliche Komponente was den Schutz meiner Systeme angeht.
Schritt 2: Detection & Analysis
Im Gegensatz zu den Wegen anderer mystischer Wesen sind die Wege der meisten Angreifer durchaus ergründlich. Vorausgesetzt man hat die richtigen Werkzeuge, um sie zu erkennen. Ein solches Werkzeug bietet beispielsweise ein EDR System, wie in meinem letzten Artikel beschrieben: Endpoint Detection and Response – wer (richtig) sucht, der findet!
Da Incident Response aber erst dann zum Zug kommt, wenn die Prävention gescheitert ist, ist es in diesem Schritt umso wichtiger, möglichst schnell zu erkennen, wo sich ein Angreifer eingenistet hat, was für Kommunikationswege aufgebaut wurden und ob vielleicht schon Daten abfliessen oder manipuliert werden.
Sofern eine EDR Lösung wie sie von CrowdStrike angeboten wird, in einem Unternehmen noch nicht verwendet wird, kann diese auch als einer der Schritte einer Incident Response grossflächig in kürzester Zeit ausgerollt werden.
Natürlich spielen bei der Erkennung aber nicht nur die Endpoint Daten eine Rolle. Wichtig sind auch die Logs anderer Komponenten wie z.B. Firewalls oder NDR Lösungen. Alle Daten zusammen ergeben ein gesamtes Bild der Bedrohungslage und helfen dabei, einen Angriff zu erkennen. Für die Konsolidierung all dieser Feeds kann ein SIEM (Security Information and Event Management) verwendet werden.
Sobald ein Vorfall analysiert und priorisiert ist, müssen je nach Schweregrad die erforderlichen Stellen informiert werden. Das betrifft in erster Linie betriebsinterne Personen, könnte aber in Zukunft auch Behörden umfassen.
Stand heute gibt es in der Schweiz noch keine gesetzlich vorgeschriebene Meldepflicht für Cybersecurity Vorfälle. Es ist also den betroffenen Unternehmen überlassen, ob sie einen Vorfall melden wollen oder nicht. Basierend auf dem Bericht «Varianten für Meldepflichten von kritischen Infrastrukturen bei schwerwiegenden Sicherheitsvorfällen» will der Bundesrat bis Ende 2020 einen Grundsatzentscheid über die Einführung einer Meldepflicht fällen. Siehe dazu den Artikel: https://www.admin.ch/gov/de/start/dokumentation/medienmitteilungen.msg-id-77526.html
Trotzt nicht vorhandener Verpflichtung sind die Zahlen, die das «Nationale Zentrum für Cybersichrheit», ehemals MELANI, auf ihrer Website veröffentlicht, interessant: https://www.melani.admin.ch/melani/de/home/ueber_ncsc/meldeeingang.html
Gerade kleinere und mittelgrosse Unternehmen werden bei einem gravierenden Vorfall komplett überfordert sein. Es empfiehlt sich daher, frühst möglich externe Spezialisten hinzuzuziehen und bereits als Teil der Vorbereitungen mit möglichen Incident Respons Dienstleistern in Kontakt zu treten.
Schritt 3: Containment, Eradication & Recovery
Um bei einem Vorfall zu verhindern, dass die aufgebotenen Incident Responder vom schieren Ausmass des Angriffs überwältigt werden, aber natürlich auch um den entstandenen Schaden möglichst klein zu halten, ist einer der wichtigsten Punkte die zügige Isolation betroffener Systeme. Abhängig vom Schweregrad des Angriffs, sollten als Teil der Vorbereitung verschiedene Eindämmungs-Strategien entwickelt werden, die ein rasches Handeln erleichtern. Beim Ausarbeiten einer solchen Strategie sollten unter anderem folgende Kriterien berücksichtigt werden:
- Potenzieller Schaden an und Diebstahl von Ressourcen
- Spurensicherung
- Service Verfügbarkeit, z.B. kritisch für Onlineshops
- Zeit und Ressourcen, die für die Anwendung der Strategie benötigt werden
- Effektivität der Strategie
- Dauer der Lösung, z.B. Notfall Workaround für x Stunden, temporärer Workaround für Tage oder Wochen, oder gar permanente Lösung
Strafrechtliche Verfolgung von Cybersecurity Vorfällen ist schwierig bis unmöglich. Nichtsdestotrotz ist eine Spurensicherung wichtig. Primär geht es bei der Spurensicherung darum, den Vorfall zu beenden, die gesammelten Beweise können aber zu einem späteren Zeitpunkt natürlich auch für rechtliche Schritte genutzt werden.
Sobald ein Angriff erstmal eingedämmt und mögliche Beweise gesichert sind, geht es daran die verschiedenen Komponenten des Vorfalls zu beseitigen. Dazu gehört unter anderem das Löschen allfälliger Malware auf Systemen, das Zurücksetzen geänderter Registry Keys, das Sperren kompromittierter Accounts oder aber gleich das Neuaufsetzen der Systeme. So geschehen im Mai 2019 bei Heise. Nachzulesen hier: https://www.heise.de/ct/artikel/Trojaner-Befall-Emotet-bei-Heise-4437807.html
Schritt 4: Post-Incident Activity
Der Mensch hat die Gabe, aus Fehlern zu lernen. Konfuzius sprach «Der Mensch hat drei Wege, klug zu handeln. Erstens durch Nachdenken: Das ist der edelste. Zweitens durch Nachahmen: Das ist der leichteste. Drittens durch Erfahrung: Das ist der bitterste.» In diesem Fall kann ein Incident durchaus als bittere Erfahrung bezeichnet werden. Wenn man aus einem solchen Vorfall jedoch seine Lehren zieht, seine Systeme entsprechend härtet, Sicherheitslücken stopft und seinen Sicherheitsaparat ggf. erweitert, so steht man nach dem Vorfall definitiv besser da als vorher. Einige Fragen die man sich im Nachhinein stellen sollte sind:
- Was ist genau passiert und wann?
- Wie gut haben sich die involvierten Teams geschlagen? Wurden die vorgängig erstellen Prozesse befolgt und waren sie zutreffend?
- Haben wichtige Informationen in den vorbereiteten Dokumenten gefehlt?
- Was würde in einem nächsten vergleichbaren Fall anders gemacht werden?
Fazit
Wie man sehen kann, geht es bei Incident Response um weit mehr als nur das Löschen eines Virus. Auch wenn man selber bis jetzt von einem ernsthaften Vorfall verschont geblieben ist, sollte man sich für den Ernstfall wappnen.
Links
Hilfe, wenn’s doch mal brennt: www.avantec.ch/services/incident-response/
Infos zu Crowdstrike: www.avantec.ch/loesungen/avantec-newcomers/#crowdstrike
Der Beitrag Endpoint Detection and Response – R wie Response erschien zuerst auf Tec-Bite.