
Deep Learning, sprich das Training und die Vorhersage mit künstlichen neuronalen Netzen bestehend aus vielen Schichten, ist einer der Treiber der vielen Fortschritte im Feld des maschinellen Lernens in den letzten 10 Jahren. Auch im Bereich der Cyber Security finden sich diverse Anwendungsfälle wie Anti-Spam, Anti-Malware und Analyse von Netzwerkverkehr (für eine Übersicht siehe Blog-Post [1]).
Die grosse Stärke von Deep Neural Networks ist die Fähigkeit, statistische Zusammenhänge in Datensätzen zu erlernen, welche dann für die Vorhersage auf bisher ungesehenen Daten aus der gleichen Verteilung genutzt werden können (sogenannte Generalisierung).
In einem früheren Artikel [2] haben wir ein Recurrent Neural Network auf Basis von 200 Tec-Bite Blog-Posts trainiert, um dann anhand von Satzvervollständigungsaufgaben zu testen, wie viel das Machine Learning Modell über Cyber Security gelernt hat. Heute ist das Ziel, in Bildern zu visualisieren, was sich ein Deep Neural Network unter verschiedenen Cyber-Security-Begriffen «vorstellt». Einleitend und als Hintergrund sprechen wir kurz über multi-modale Modelle, GANs und deren Kombination in ein Text-zu-Bild-Modell.
Multi-modale Modelle (CLIP)
Seit 2-3 Jahren wird viel Forschung betrieben, um multi-modale Modelle zu designen und zu trainieren. Dies sind Modelle, die verschiedene Medien-Formate wie Bild und Text nicht nur wie bisher über eine lernbare Input-Output-Beziehung verknüpfen, sondern die Inhalte in einen gemeinsamen Vektorraum projiezieren. OpenAI CLIP [3] ist ein Modell, welches mit 400 Millionen Paaren von im Internet frei verfügbaren Bildern mit Beschriftung so trainiert wurde, dass die sogenannten Embeddings von einem entsprechenden Bild und dessen Text in diesem Vektorraum «nahe» beieinander liegen. So können semantische Ähnlichkeiten respektive Distanzen zwischen Bildern und Texten abgefragt werden. Das funktioniert auch mit Inhalten (Bildern oder Text), die CLIP im Training nie gesehen hat erstaunlich gut («zero-shot learning»).
Generative Adversarial Networks (GAN)
Ein anderer interessanter Teilbereich des Deep Learnings sind die sogenannten GAN-Architekturen. Diese bestehen aus zwei konkurrenzierenden neuronalen Netzen, bei denen das eine im Training die Aufgabe hat, Bild-Kandidaten zu generieren und das andere diese bewertet und von «echten» (d.h. nicht künstlich generierten) Bildern zu unterscheiden. Durch dieses Verfahren können iterativ immer schwieriger zu unterscheidende (d.h. «echt aussehende») Bilder generiert werden. VQGAN [4] ist eine solche GAN-Architektur.
Kombination von CLIP und VQGAN in ein Text-zu-Bild-Modell
Durch die Verkettung von CLIP mit VQGAN kann VQGAN bei der Erstellung eines Bildes iterativ so gesteuert werden, dass dieses möglichst nah an ein vordefiniertes Stichwort herankommt. Grob funktioniert dies ungefähr so wie unten dargestellt: CLIP beurteilt ein von VQGAN generiertes Bild auf «Nähe» zum gesuchten Stichwort und gibt VQGAN Feedback, damit das nächste zu erstellende Bild näher beim Text-Begriff zu liegen kommt.
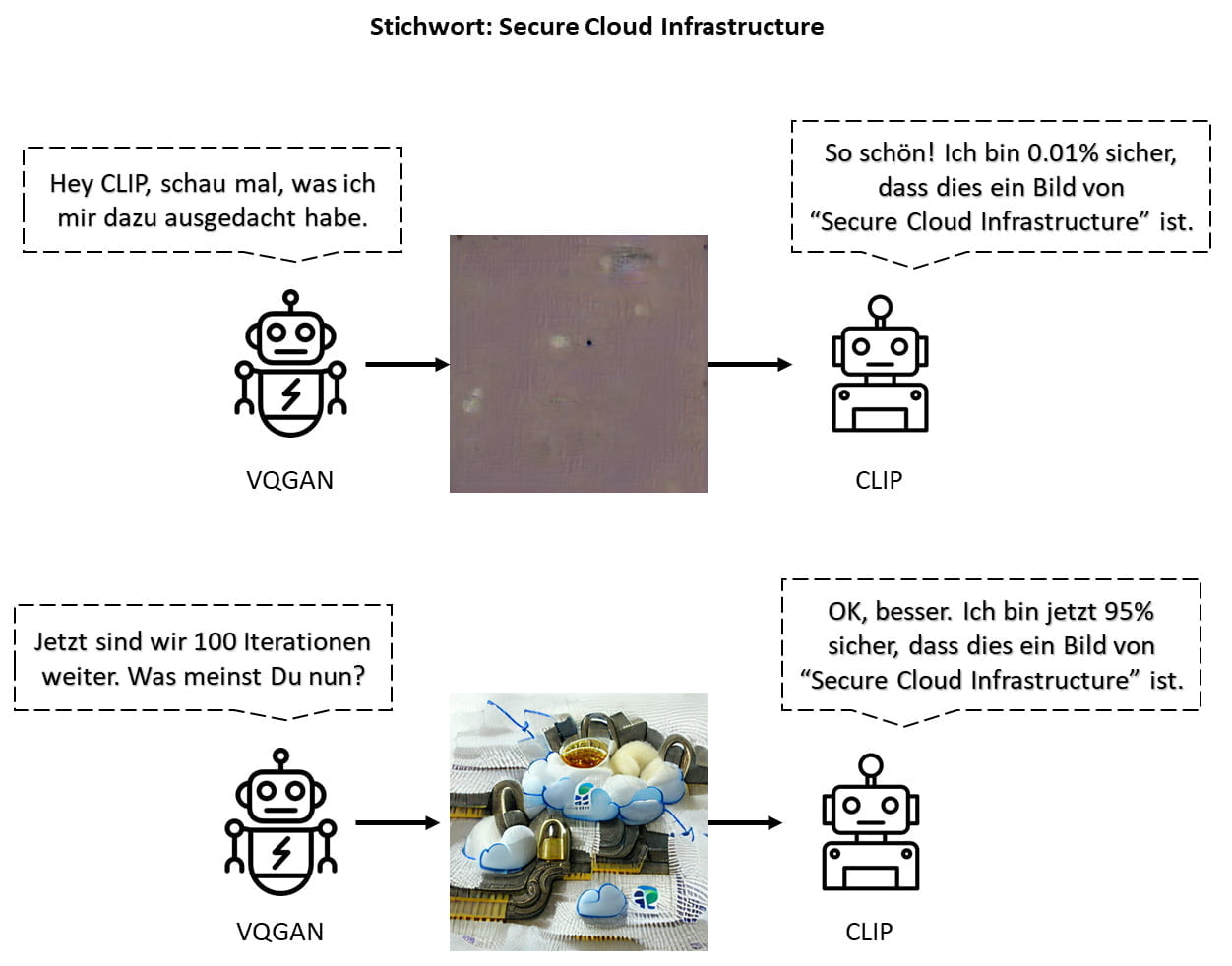
Bild-Generierung basierend auf Cyber-Security-Begriffen
Welche Bilder VQGAN unter der Anleitung von CLIP auf Basis verschiedener Stichwörter oder Kurzsätze aus dem Kontext Cyber Security generiert, ist in folgender Collage festgehalten. Es ist insbesondere interessant zu sehen, wie diverse abstrakte Begriffe durch konkrete Verbildlichungen visualisiert werden (Malware durch Käfer, Infrastruktur durch Schienen, Sicherheit durch Vorhängeschloss).

Der Beitrag Was sich ein Deep Neural Network unter Cyber Security vorstellt… erschien zuerst auf Tec-Bite.