
Wege in eine passwortlose Zukunft – aber woran haperts?

Kompromittierte Kontoinformationen sind eine der Hauptursachen für Datenschutzverletzungen. Deshalb setzen auch grosse Cloud-Anbieter wie Microsoft und Google auf «Passwordless»-Methoden. Die passwortlose Authentifizierung ist ein Mittel zur Überprüfung der Identität eines Nutzers, ohne ein Passwort zu verwenden. Stattdessen werden bei der passwortlosen Authentifizierung sichere Alternativen wie Besitzfaktoren bzw. Hardware-Tokens oder z.B. Mobile Devices verwendet.
Dazu kommt: Immer mehr Unternehmen weiten derzeit ihre digitale Transformation aus und migrieren in die Cloud. Diese Unternehmen stehen vor der Herausforderung, sich mit einer ganzen Reihe neuer Anwendungsfälle befassen zu müssen, beispielsweise mit Sicherheitsverletzungen aufgrund von Identitätsdiebstahl, weil sie bislang unter Umständen nur in einen Authentifizierungsstandard investiert haben.
FIDO 2.0 als «Passwordless»-Lösung
Beim Begriff FIDO, der für «Fast Identity Online» steht, handelt es sich um eine Reihe plattformunabhängiger zertifizierter Authenticator Tokens – oder: token on mobile devices –, welche den Benutzeranmeldeprozess für Onlinedienste härten, die auf Kryptografie mit öffentlichen Schlüsseln und elliptischen Kurven basieren. Die Standards werden von der FIDO Alliance entwickelt und fördern schnellere und sichere Authentifizierungsprozesse mit dem übergeordneten Ziel, passwortbasierte Anmeldungen, auch One-Time Passwords, zu eliminieren. Vereinfacht gesagt, handelt es sich um einen Standard, der ohne Zertifikate, jedoch asymmetrisch (via Public Key und Private Key) zur Anwendung gelangt.
Wird FIDO im Zusammenspiel mit einem biometrischen Verfahren bzw. einem zweiten lokalen (und nicht übertragbaren Faktor) wie beispielsweise einem Fingerprint ausgehandelt, handelt es sich dennoch um eine asymmetrische Authentisierung, da die biometrischen Informationen nur lokal als zweiter Faktor verwendet werden, auch wenn das symmetrische Verfahren sind.
In der Cloud, beim IdP, wird jeweils nur der Public Key gespeichert und der Private Key bleibt immer lokal, basierend auf der FIDO-Zertifizierung, geschützt und nicht übertragen. (Nur der sogenannte «Nonce», eine einmalige Zufallszahl in der kryptographischen Kommunikation oder die mit dem Private Key verschlüsselte Version bzw. der verschlüsselte «Hash» geht durch die Leitung.)
Anwendungsszenarien des consumernahen FIDO-Standards
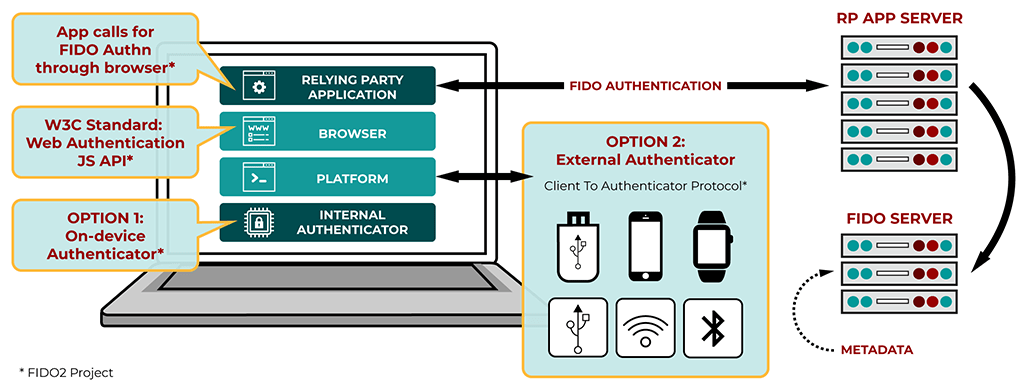
Quelle: https://fidoalliance.org/specifications, abgerufen am 20.09.2023
Worin sich PKI und FIDO 2.0 unterscheiden
Die Geschichte von Public Key Cryptography begann bereits in den frühen 1970er-Jahren im Zuge wichtiger Entdeckungen zu Verschlüsselungsalgorithmen beim britischen Geheimdienst. Anders als FIDO 2.0 stützt sich PKI mit den digitalen Zertifikaten auf die Dienste einer vertrauenswürdigen Stelle Certificate Authority (CA), welche den Lifecycle eines kryptographischen Schlüssels mit digitalen Zertifikaten abbildet. Mögliche Anwendungen beinhalten: SSL für Webserver und Webdienste, WLAN- bzw. LAN-Authentifizierung, Smart-Card-Anmeldung, E-Mail-Verschlüsselung, E-Mail-Signaturen und Dokumentensignaturen.
Wie bei FIDO wird bei einer PKI ein Paar kryptographischer Schlüssel (Private and Public Key) verwendet. Das Schlüsselpaar wird beim Requestor erzeugt und die CA signiert die beschreibenden Informationen im Zertifikat mit dem Public Key. Diese digitale Signatur kann von jedem mit dem Public Key der CA verifiziert werden. So ermöglicht diese Hierarchie das Hinterlegen eines CA-Zertifikats, wodurch quasi alle Client-Zertifikate verifiziert werden. Bei FIDO handelt es sich demgegenüber immer um ein «1:1-Mapping».
Schema einer PKI-Architektur
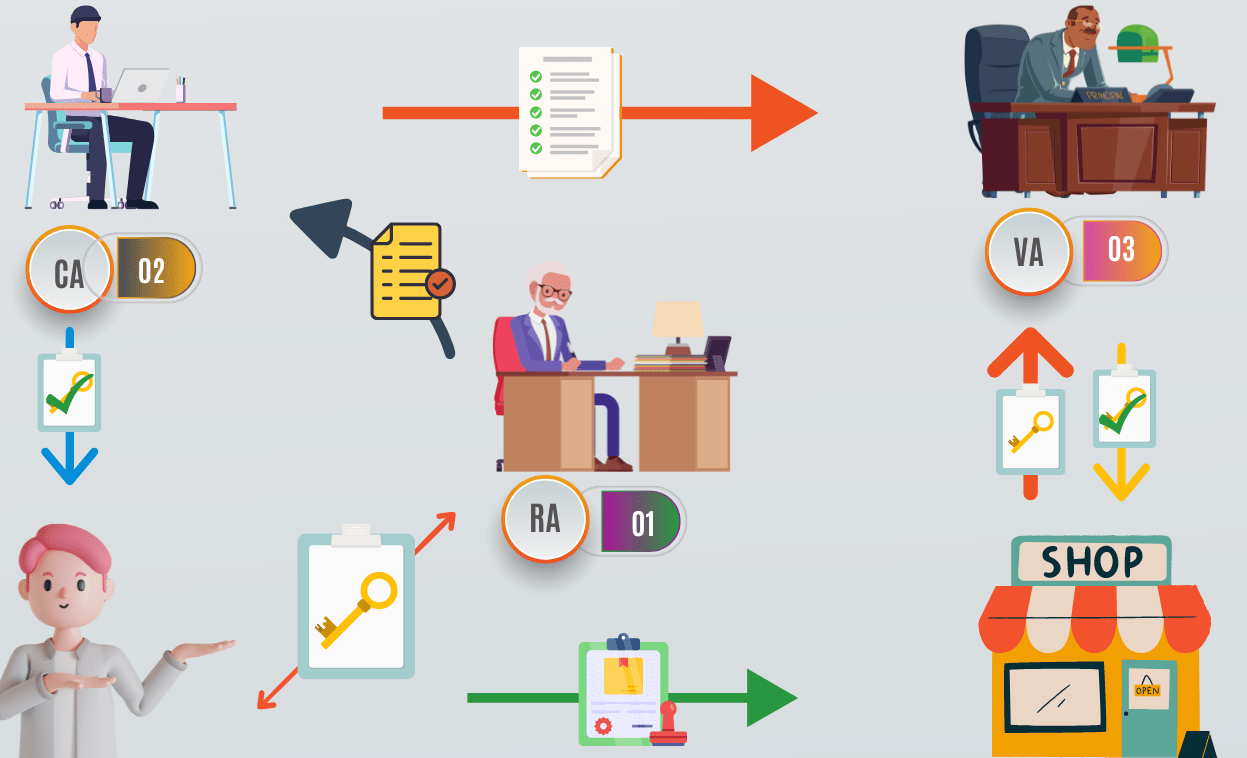
Quelle: Fiverr/Alina Farooqi
CA: Certification Authority
RA: Registration Authority
VA: Validation Authority
Wo es auf Enterprise-Ebene komplex wird
Die Sicherheitsanforderungen steigen durch eine schnelle Nutzung der Cloud-Infrastrukturen und der Multiplizierung von Endgeräten. Hinsichtlich der Implementierung von PKI bestehen ausserdem Einschränkungen bei Cloud-Anwendungen. So kann PKI-Authentifizierung nicht so leicht auf mobile Geräte angewandt werden. Zudem sind PKI-Szenarien teilweise auf etablierte bzw. Enterprise-Anwendungen via VPN beschränkt.
Wie jedes Sicherheitssystem weist aber auch FIDO einige Nachteile auf. Zwar kann FIDO bei Usecases wie Webadmins oder Fabrikmitarbeitenden Sinn ergeben, da die Anwender unter Umständen kein persönliches Smartphone zur Identifikation mitnehmen möchten. Hier benötigt FIDO keine Zertifikate und man spart sich Kosten und Aufwände; erkauft sich jedoch auch genau jene Nachteile damit. Schliesslich stehen bei Zertifikaten auch Kriterien wie «Validity», «Period» und «Revocation» im Fokus, da ein Zertifikat immer ein Anfangs- und Enddatum beinhalten kann, ab dem es gültig und nicht mehr gültig ist, zumal Enddaten sehr oft anfallen, da die meisten Zertifizierungsstellen es für sinnvoll erachten, ein Zertifikat von Zeit zu Zeit zu erneuern.
So lässt sich nicht nur überprüfen, ob der Inhaber noch echt ist («Trust»), sondern auch ein Zertifikat unter bestimmten Umständen wiederrufen wurde («Revoke»). Dies ist beispielsweise dann erforderlich, wenn der zugehörige private Schlüssel des Inhabers verlorengeht oder die Zertifizierungsstelle dessen Inhaber nicht mehr als vertrauenswürdig erachtet.
Was passiert aber beispielsweise, wenn zu viele Registrierungen mit einem FIDO-Token vorgenommen werden? Was passiert, wenn ein Mitarbeitender sich mit seinem FIDO-Token bei Webservices registriert, die nicht von der Firma vorgesehen sind? Der Nachteil von FIDO liegt daher nicht selten in der Komplexität jener Ausschlussfaktoren begründet, wenn beispielsweise ein Mitarbeitender das Unternehmen verlässt.
Probleme, die sich nur mit einem Identitätsprovider (IdP) lösen lassen
FIDO ermöglicht daher meist nur die Authentifizierung, respektive die sichere Wiedererkennung. Zur Schaffung einer digitalen Identität müssen Authentifizierung und die Identität vom Identitätsanbieter zusammengeführt werden. Hier gelangt ein Identitätsprovider (IdP) zur Anwendung. Da jeder User sich selbst bei allen verwendeten Webservices registrieren muss, ist ein zentraler Authentisierungsdienst (Identity Provider – IdP) notwendig, um den Lifecycle der Token der Mitarbeitenden zu verwalten. Dies umfasst unter anderem die Kriterien:
- Registrierung
- Verwaltung der User-Tokens
(Welcher User verwendet welches Token?) - Validity: Da diese nicht wie bei einem Zertifikat gegeben ist, müssen wir diese für die Mitarbeitenden auf dem IdP realisieren bzw. den Account deaktivieren.
- User-Self-Service: Wie sich Mitarbeitende selbst helfen, damit die User sich online ohne Helpdesk jederzeit neue Credentials zustellen lassen können.
Der IdP verwaltet nebst der Policies für Compliance, Access Control und Re-Authentification vordergründig das Enrollment bzw. die Public Keys des FIDO-Schlüsselpaares. Der Zugriff auf die eigentlichen Webanwendungen erfolgt dann mit Security Assertion Markup Language (SAML) oder OpenID Connect (OIDC). Bei ersterem handelt es sich um eine XML-basierte Auszeichnungssprache bzw. ein Protokoll verschiedener Dienstanbieter wie Office 365, Salesforce und Zoom, während OpenID Connect einer Reihe von (webbasierten, mobilen) Clients den Informationsaustausch über authentifizierte Sessions und Anwender ermöglicht.
Anwendungsszenarien genau evaluieren
Es lohnt sich, die Bedürfnisse im Unternehmen genau zu identifizieren. Sind es beispielweise temporäre Mitarbeitende eines Unternehmens? Werden Cloud- und Webzugriff, FIDO-Badge-Zugriff oder gar eine Hybrid-PKI-FIDO-Lösung benötigt, beispielsweise für digitale Signaturen und Verschlüsselung? Manchmal kann auch exemplarisch eine Smart Card wie IDPrime mit FIDO oder ein eToken Fusion von Thales (ehemals Gemalto) eine Lösung sein, welche sowohl PKI-Szenarien als auch FIDO-Authentifizierung unterstützt und zur physischen Zutrittskontrolle mit RFID wie z.B. kontaktloser Chipkartentechnik nach Legic (in der Schweiz zu 90 Prozent), Mifare Classic & Desfire kompatibel bleibt.
Fazit
FIDO bietet vor allem für mobile Geräte eine hochsichere Passwordless Authentification, die nun seit Anfang 2023 auch in Azure genutzt werden kann. (Certificate-based Authentication mit Zertifikaten einer eigenen PKI sowie Smart-Card-Anmeldung sind dadurch nun auch bei Azure möglich.) So lassen sich grundsätzlich keine Credentials mehr erbeuten. Auch Phishing-Angriffe laufen dann ins Leere. Man fängt sich mit FIDO aber auch ein paar Nachteile ein, da es im Wesentlichen nur um Key-based Authentication für Consumer handelt.
Die Vorteile eines Zertifikats mit Trust, Validity, Revocation und Managed Devices auf Enterprise-Ebene müssen daher bei den Einsatz von FIDO durch einen zentralen IdP kompensiert werden. Das kann Azure sein oder eine Kombination von Card-Management-Systemen sowie eines geeigneten IdP (wie beispielsweise vSEC: CMS & Thales STA). Dort werden die FIDO-Token für die Benutzer im «Send-to-All-Modus» pre-provisioniert und können dann für den Zugriff auf die Unternehmensapplikationen verwendet werden. Die Smart Cards werden wie üblich vollständig vorbereitet und der Enduser bekommt die Karte und die PIN.
Smart Cards decken ein umfassenderes Anwendungsspektrum ab – wie Authentisierung, Signaturen und Verschlüsselungsapplikation. Eine Kombination von allen Möglichkeiten böte aber wohl die grösste Zukunftssicherheit.
Weiterführende Links
Der Beitrag Wege in eine passwortlose Zukunft – aber woran haperts? erschien zuerst auf Tec-Bite.

Neues Datenschutzgesetz – was müssen Firmen wissen?

Unternehmen müssen seit diesem Monat einige verschärfte Regeln im Umgang mit Personendaten beachten. Dreh- und Angelpunkt ist das neue Datenschutzgesetz (nDSG oder revDSG), dessen Bestimmungen seit dem 1. September 2023 gelten. In diesem Artikel erfahrt ihr, was sich geändert hat und wie sich Unternehmen darauf einstellen können.
Warum brauchten wir eine Änderung?
Das alte Datenschutzgesetz aus dem Jahr 1992 war, gemessen an der heutigen Technologiewelt, wie aus der Steinzeit. Seitdem hat sich enorm viel verändert. Als das alte DSG in Kraft trat, wurde das WWW erst gerade erfunden. Das Gesetz war einfach nicht mehr zeitgemäss für Datenkraken, Cloud-Dienste, AI, IoT, Smartphones usw. Aber nicht nur das, die Schweiz stand auch unter Druck, ihre Datenschutzstandards an die EU (DSGVO) anzugleichen, um den freien Datenverkehr mit der EU erhalten zu können.
Die Überarbeitung des DSG hatte vier Hauptziele:
- Mehr Transparenz: Unternehmen müssen jetzt darüber informieren, wie sie persönliche Daten verarbeiten und den betroffenen Personen mehr Kontrolle über ihre Daten geben.
- Förderung von Prävention und Eigenverantwortung: Die revidierten Bestimmungen ermutigen Datenverarbeiter, proaktiv Schutzmassnahmen zu ergreifen und sicherzustellen, dass sie die Datenschutzvorschriften einhalten.
- Stärkung der Datenschutzaufsicht: Die Überwachung der Einhaltung der Datenschutzbestimmungen durch den Eidgenössischen Datenschutz- und Öffentlichkeitsbeauftragten (EDÖB) wird verstärkt.
- Verschärfung der Strafen: Die Strafen für Verstösse gegen das Datenschutzgesetz wurden verschärft und es wurden neue Strafbestände geschaffen.
Die wichtigsten Änderungen im Überblick
Lasst uns einen Blick auf die wichtigsten Änderungen werfen:
- Juristische Personen sind nicht mehr geschützt: Das neue DSG schützt nur noch natürliche Personen. Unternehmen können sich nicht mehr auf das Gesetz berufen und müssen sich stattdessen auf das Firmenrecht und andere bestehende Gesetze verlassen.
- Besonders schützenswerte Personendaten: Die Liste der besonders schützenswerten Personendaten wurde erweitert, um auch genetische und biometrische Daten einzuschliessen. Dies hat Auswirkungen auf die Einwilligung, Datenschutz-Folgenabschätzungen und die Weitergabe von Daten an Dritte.
- Profiling und Profiling mit hohem Risiko: Profiling ist die automatisierte Bewertung von persönlichen Aspekten einer Person. Wenn es ein hohes Risiko birgt, muss die betroffene Person ausdrücklich zustimmen.
- Auftragsbearbeiter: Unternehmen, die Daten auslagern, müssen (wie bislang) sicherstellen, dass ihre Auftragsbearbeiter die Datensicherheit gewährleisten können. Die Übertragung an Unterauftragnehmer erfordert die Genehmigung des Verantwortlichen.
- Datenschutz durch Technik und datenschutzfreundliche Einstellungen: Unternehmen müssen von Anfang an sicherstellen, dass die Datenschutzvorschriften eingehalten werden (Privacy by Design). Die Standardeinstellungen müssen so eingestellt sein, dass die Datenverarbeitung auf ein Minimum beschränkt ist (Privacy by Default).
- Neue Informationspflichten: Unternehmen müssen betroffene Personen über die Identität des Verantwortlichen, den Verarbeitungszweck und weitere Informationen informieren, insbesondere wenn Daten ins Ausland übertragen werden. Gemäss dem bislang geltenden DSG genügte die Erkennbarkeit der Bearbeitung von Personendaten.
- Ausbau der Auskunftspflichten: Betroffene Personen haben das Recht, alle Informationen zu erhalten, die sie für die Geltendmachung ihrer Datenschutzrechte nach dem revidierten DSG benötigen.
- Recht auf Datenübertragbarkeit: Betroffene Personen können die Herausgabe ihrer Personendaten oder deren Übertragung an einen anderen Verantwortlichen in maschinenlesbarer Form verlangen.
- Automatisierte Einzelfallentscheidungen: Personen müssen über Entscheidungen informiert werden, die ausschliesslich auf automatisierter Verarbeitung beruhen und erhebliche Auswirkungen auf sie haben. Sie haben das Recht, diese Entscheidungen überprüfen zu lassen.
- Datenschutz-Folgenabschätzung: Unternehmen müssen eine Datenschutz-Folgenabschätzung durchführen, wenn die Datenverarbeitung ein hohes Risiko für die Rechte und Freiheiten betroffener Personen darstellen kann.
- Meldung von Datenschutzverletzungen: Bei Datenschutzverletzungen müssen Unternehmen diese dem EDÖB und unter bestimmten Umständen auch den betroffenen Personen melden.
- Sanktionen: Das revidierte DSG sieht Geldstrafen bis zu 250’000 Franken für natürliche Personen vor, die vorsätzlich gegen die Datenschutzbestimmungen verstossen. Unternehmen und verantwortliche Personen können nun direkt sanktioniert werden. Im Gegensatz dazu, sind im DSGVO Bussen nur für Unternehmen vorgesehen. Dafür können Bussen aber bis zu 4 Prozent des gesamten weltweit erzielten Umsatzes betragen. Im Fall der UBS wären das ca. 300 Millionen US-Dollar.
Was Unternehmen jetzt tun sollten
Falls noch nicht bereits geschehen, sollte eine Bestandsaufnahme der Datenverarbeitungen durchgeführt werden. Dies sollte im Rahmen einer Gap-Analyse geschehen, um den Handlungsbedarf im Bereich Datenschutz zu ermitteln. Es ist wichtig zu beachten, dass die Datenschutz-Compliance ein kontinuierlicher Prozess ist und keine einmalige Aufgabe. Unternehmen sollten einen Monitoring- und Review-Prozess implementieren, um auf Veränderungen in ihren Datenverarbeitungspraktiken reagieren zu können.
Darüber hinaus ist es entscheidend, Mitarbeiter auf Datenschutzfragen zu sensibilisieren und zu schulen. Dies stellt sicher, dass sie sich keiner persönlichen Strafbarkeit aussetzen und das Unternehmen nicht Gefahr läuft, Sanktionen oder Reputationsschäden zu erleiden.
Nach einer Empfehlung gefragt, empfiehlt Martin Steiger, Anwalt für Recht im digitalen Raum, das Datenschutz-Management auf die Vermeidung eigener Risiken auszurichten. Wer Datenschutz so lebt, dass die Wahrscheinlichkeit für Sanktionen oder Reputationsschäden gering ist, schützt automatisch die betroffenen Personen vor Datenschutzverletzungen. Ärger mit Behörden und betroffenen Personen provozieren Unternehmen meist selbst, beispielsweise durch Datenpannen oder wenn Auskunftsbegehren nicht schnell und vollständig genug beantwortet werden.
Insgesamt bringt das revidierte Schweizer Datenschutzgesetz wichtige Änderungen mit sich, die Unternehmen beachten müssen, um die Einhaltung der Datenschutzbestimmungen sicherzustellen und mögliche rechtliche Konsequenzen zu vermeiden.
Weiterführende Links:
Der Beitrag Neues Datenschutzgesetz – was müssen Firmen wissen? erschien zuerst auf Tec-Bite.

Cyber Security: Ist teuer auch gleich besser?

Die Welt der Cyber-Bedrohungen entwickelt sich kontinuierlich weiter. Die Organisationen dahinter sind erfolgreich und reinvestieren ihre Gewinne in neue Angriffsmethoden und Technologien. Unternehmen, die sich und ihre Daten nachhaltig schützen wollen, dürfen nicht stehenbleiben und müssen ihre Verteidigungsstrategien und Abwehrmechanismen regelmässig überdenken bzw. optimieren. Dabei stellt sich ganz generell die Frage, wie viel IT-Security kosten darf?
In diesem Blogartikel möchte ich euch aufzeigen, warum es sich lohnen kann nicht zu geizen und warum teure Lösungen tatsächlich einen besseren Schutz leisten können gegen die wachsende Anzahl von Cyber-Bedrohungen.
Advanced Threat Detection & Prevention
Teure Cybersecurity-Lösungen beinhalten häufig Mechanismen für Advanced Threat Detection & Prevention. Diese Ansätze werden bewusst entwickelt, um hochentwickelte Angriffe erkennen zu können, ohne auf Datenbanken mit bestehenden Bedrohungsmustern angewiesen zu sein. Damit sollen auch Zero Days, polymorphe Malware und ganz generell einzigartige und gezielte Angriffe erkannt und blockiert werden. Grosse Investments in Forschung und Entwicklung ermöglichen es diesen Produkten, mit den Angreifern und ihren Methoden mitzuhalten und ein besseres Schutzlevel zu erreichen.
Real-Time Monitoring & Response
Cybersecurity-Produkte im oberen Preissegment sind oft auf Real-time Monitoring & Response ausgelegt. Bedrohungen werden dabei umgehend erkannt und Massnahmen eingeleitet, damit die Zeit, in der Angreifer ihr Unwesen im Netzwerk treiben können, reduziert wird und der Schaden für das Unternehmen minim bleibt. Prävention ist nicht immer möglich, die Reaktionszeit und die Durchführung von vordefinierten Massnahmen sind daher der kritische Faktor, um Datendiebstahl oder andere bösartige Aktivitäten zu verhindern bzw. deren Schadensausmass zu reduzieren.
Umfassende und kundenspezifische Konfigurationsmöglichkeiten
Während günstige Optionen einen guten Basisschutz bieten, beinhalten teure Lösungen mehr Features und mehr Konfigurationsmöglichkeiten. Richtig eingesetzt können Unternehmen, damit ihre Security-Bedürfnisse besser abdecken bzw. mit ihren Anforderungen und Policies in Einklang bringen. Unternehmen mit hohen Security-Bedürfnissen möchten eine massgenschneiderte Verteidigungsstrategie umsetzen und nicht nur auf Standard-Security vertrauen.
Regelmässige Updates und Upgrades
Cybersecurity-Bedrohungen sind sehr dynamisch und entwickeln sich ständig weiter. Es ist entscheidend, dass Updates bzgl. neuen Angriffsmustern umgehend zur Verfügung gestellt und eingespielt werden. Hinter teuren Produkten und Services stehen in der Regel dedizierte Teams, welche laufend und erfolgreich Updates, Patches und Upgrades entwickeln, damit Kunden umgehend vor neuen Bedrohungen geschützt sind.
Optimale Betreuung durch technische Experten
Hersteller mit Cybersecurity-Lösungen im oberen Preissegment legen hohen Wert auf die Ausbildung, Expertise und Erfahrung ihrer Partner. Der lokale Integrations- und Supportpartner hilft den Unternehmen, die Lösung korrekt zu konfigurieren und optimal einzusetzen. Die richtige Konfiguration ist entscheidend, um den grössten Mehrwert aus einer Lösung herauszuholen. Gute Partner bringen Best Practice mit, helfen mit ihrer Expertise sowohl im täglichen Betrieb als auch bei Vorfällen.
Reduktion von False Positives
Ausgereifte Lösungen schaffen es, mithilfe von weitentwickelten Algorithmen und Machine Learning die False-Positive-Rate zu reduzieren. False Positives haben zwei grosse Nachteile: Erstens sind sie Zeitfresser und binden wichtige Ressourcen. Zweitens führen zu viele False Positives dazu, dass die entsprechenden Alerts an Bedeutung verlieren und die kritischen Fälle in der Masse untergehen. Durch die Minimierung von Falschmeldungen können sich die Security-Experten im Unternehmen auf die wenigen wirklich relevanten Security Incidents fokussieren.
Fazit
Natürlich ist teuer nicht immer gleich besser, aber häufig gibt es einen guten Grund, warum eine Lösung mehr kostet. Ein reiner Produktvergleich mittels Datenblätter und Features-Katalog bringt diese versteckten, aber wichtigen Unterschiede meist nicht ans Licht und ist daher sehr gefährlich, wenn es darum geht, die richtige Entscheidung für eine nachhaltige und robuste Cyber-Security-Lösung zu treffen. Der Mehrwert einer Cyber-Security-Lösung hängt letztendlich stark von seiner Innovationskraft, den Forschungs- und Entwicklungsressourcen dahinter und der Fähigkeit ab, rasch auf eine sich stetig ändernde Bedrohungslage zu reagieren. Berichte von Analysten, eine langjährige Reputation und Referenzgespräche mit bestehenden Kunden können helfen ein vollständigeres Bild zu bekommen. Auf jeden Fall sollte bei einem so wichtigen Thema wie Cyber Security nicht ausschliesslich auf den Preis geachtet werden, TCO-Überlegungen (Total Cost of Ownership) berücksichtigt und günstige Optionen kritisch hinterfragt werden.
Der Beitrag Cyber Security: Ist teuer auch gleich besser? erschien zuerst auf Tec-Bite.

Cloud Detection and Response (CDR) – ein Must-have?

Unternehmen setzen immer mehr auf Cloud-Plattformen – kaum noch jemand bezieht keine Services aus der Cloud. Während dies durchaus auch positive Einflüsse auf die Security hat, gibt es leider auch negative Seiten. Jüngstes Beispiel: Der spektakuläre Hack von chinesischen Angreifern mittels eines gestohlenen Microsoft Signing Keys. Verhindern lassen sich solche Angriffe eigentlich nicht, mit den richtigen Tools kann man diese aber detektieren und darauf reagieren. Die Lösungen laufen unter dem Namen «Cloud Detection and Response» (CDR). Im Folgenden möchte ich erläutern, wie das funktioniert und warum es so wichtig ist.
Was ist Cloud Detection and Response (CDR)?
Cloud Detection and Response (CDR) sind Security-Lösungen, welche speziell für die Cloud entwickelt wurden. Sie umfassen die kontinuierliche Überwachung, Erkennung und Reaktion auf Sicherheitsbedrohungen in Cloud-Diensten.
Klassischerweise lassen sich die Tools über APIs zu den verschiedenen Diensten integrieren, darüber werden meist Audit-Logs bezogen und analysiert. CDR-Plattformen setzen meist auf maschinelles Lernen und Verhaltensanalyse, um verdächtige Aktivitäten und Anomalien zu erkennen. Die Cloud-Provider bieten meist ähnliche Funktionen direkt an, gehen aber nicht so weit wie etablierte Lösungen, wie z.B. Vectra oder CrowdStrike. Die Lösungen bieten zudem den Vorteil, dass sie über mehrere Anbieter funktionieren und auch Informationen aus der On-Premise-Welt integrieren. Da alles über APIs läuft, ist die Integration meist innert kürzester Zeit durchgeführt.
Warum ist CDR so wichtig?
1. Realtime Detection
CDR ermöglicht eine sofortige Erkennung von Bedrohungen, bevor diese zu ausgewachsenen Sicherheitsproblemen führen. Egal ob kompromittierte Accounts, maliziöse Konfigurations-Anpassungen oder ein Insider-Threat, welcher Files aus dem SharePoint abzieht, CDR wird dies innert kürzester Zeit detektieren.
2. Automatic Response
Wie von EDR- oder NDR-Tools bekannt, kann auch CDR so konfiguriert werden, dass bei Bedrohungen automatische Gegenmassnahmen eingeleitet werden. Ein Beispiel dafür wäre das Sperren von einem kompromittierten Account.
3. Adaptability
CDR-Lösungen sind darauf ausgelegt, sich an den ständigen Wandel in der Cloud anzupassen. Neue Bedrohungen können so effizient erkannt werden. Die Tools werden deshalb oftmals selbst aus der Cloud bezogen.
4. Insider Threats
CDR detektieren nicht nur Angreifer in der Cloud, sondern können auch Insider Threats, bei denen legitime Benutzer unbefugt auf sensible Daten zugreifen, sehr effektiv aufspüren.
5. Compliance und Datenschutz
Die Überwachung von Aktivitäten in der Cloud hilft dabei, Compliance-Richtlinien einzuhalten und damit den Datenschutz zu gewährleisten.
Fazit, TLDR
In einer Zeit, wo die Cloud-Nutzung immer mehr zunimmt, ist Cloud Detection and Response (CDR) ein Must-have, um die wachsenden Bedrohungen in der Cybersicherheit zu bewältigen. Mit der Fähigkeit, Bedrohungen in Echtzeit zu erkennen und automatisch darauf zu reagieren, können Unternehmen sensible Daten und Ressourcen wirksam schützen. Die Investition in eine moderne CDR-Lösung oder einen entsprechenden Service sollte daher unbedingt geprüft werden.
Weiterführende Links:
Der Beitrag Cloud Detection and Response (CDR) – ein Must-have? erschien zuerst auf Tec-Bite.

Erhöhung der Cyber Resilience: Cybersecurity-Vorfälle richtig trainieren

Ein wesentlicher Bestandteil der Cyber Resilience ist das aktive Beüben von etablierten Betriebsabläufen. Dies betrifft aber nicht nur die Backup- und Recovery-Prozeduren, sondern generell die Response-Fähigkeit auf Cybersecurity-Vorfälle. Hier ist es besonders wichtig, im Ernstfall möglichst keine Zeit verlieren und die richtigen Entscheide treffen. Wie können wir dies aber gezielt trainieren? Diesen Fragen gehe ich in meinem Blogbeitrag nach. Wir werden dem Thema Trainieren von Cybersecurity-Vorfällen eine Blogserie widmen. Unser erster Teil zeigt auf, warum Trainings unerlässlich sind, welche Voraussetzungen sie benötigen und welche Varianten von Trainings existieren.
Training ist unerlässlich!
Macht es Sinn, Cybersecurity-Vorfälle trainieren? Diese Frage kann relativ einfach beantwortet werden. Es macht definitiv Sinn. Denken Sie zum Beispiel an die Feuerwehr. Eine Feuerwehr ohne Trainings kann man sich nicht vorstellen. Nur wer regelmässig trainiert, ist für den Ernstfall gewappnet. Dies gilt in der Regel für sämtliche Arbeitsprozesse. Für gewisse Arbeitsprozesse sind aber Trainings noch wichtiger als für andere. Zu diesen Prozessen gehört auch der Incident-Response-Prozess. Gründe dafür sind unter anderem, dass es wenige Echtfälle gibt, Arbeiten zeitkritisch sind, fehlerhafte Handlungen grosse Konsequenzen zur Folge haben (z.B. wenn ein Angreifer höhere Privilegien erlangt) oder falsche Entscheide auch grosse finanzielle Schäden verursachen können (siehe Abbildung 1).
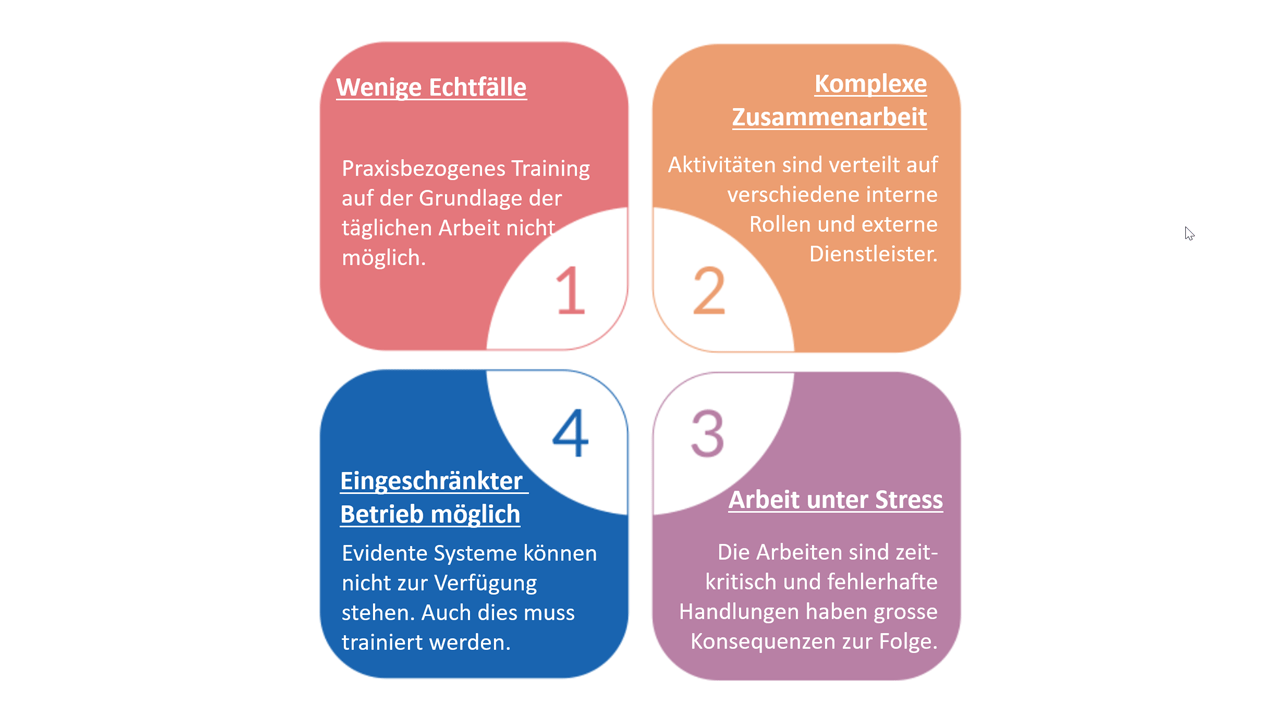
Abbildung 1: Gründe weshalb Trainings unerlässlich sind.
Ohne Prozess macht Trainieren keinen Sinn
Grundsätzlich muss man keine Voraussetzung erfüllen, um etwas zu trainieren. Um aber einen sinnvollen Nutzen aus einem Training zu erzielen, sollte mindestens ein Incident-Response-Konzept und/oder ein Incident-Response-Prozess spezifiziert und dokumentiert sein. Dann sind in der Regel Aktivitäten auf Rollen verteilt und rudimentäre Arbeitsabläufe definiert. In der Regel sind mindestens Aktivitäten für vier Teams definiert: IT-Teams, Incident Response Teams, Major Security Incident Team (Teile des Senior Managements für schwerwiegende Vorfälle) sowie ein Krisenstab, sofern vorhanden. Ein mögliches Training kann sich nun an den Teams und den definierten Aktivitäten orientieren und es können konkrete Schwachstellen identifiziert und Verbesserungsmassnahmen empfohlen werden.
Verschiedene Trainingsarten führen zum Ziel
Es gibt verschiedene Trainingsziele. Es kann sowohl in die Breite (mittels Involvierung möglichst aller Rollen) als auch in die Tiefe (im Rahmen möglichst detaillierter Tätigkeiten) trainiert werden. Es empfiehlt sich, in einem ersten Schritt in die Breite und mit fortschreitender Trainingsaktivität immer mehr in die Tiefe zu trainieren. Diese unterschiedlichen Ziele werden in der Regel mit unterschiedlichen Trainingsarten adressiert:
- Process Walk-Through (WT)
Durch einen Prozess-Walk-Through kommen die Rollen/Teams in Kontakt mit dem Prozess und lernen ihre Verantwortlichkeiten kennen. Sie machen sich vertraut mit dem Arbeitsabläufen und bauen Berührungsängste ab. - Table-Top-Exercise (TTX)
In einer zweiten Phase werden mittels Tabletop-Übungen Schwachstellen im Prozess sowie in den zur Verfügung stehenden Hilfsmittel identifiziert. Dabei machen die Teilnehmer auch erste Erfahrungen mit dem Prozess und beginnen ein Selbstvertrauen im Umgang mit Cybersecurity-Vorfällen zu entwickeln. Darauf aufbauend können Schnittstellen zwischen den Rollen beübt werden. - Trainings für technische Betriebsabläufe / Simulation-Exercise (SX)
In einer dritten Phase können dann technische Betriebsabläufe trainiert werden. Beispiele von technischen Simulations-Trainings sind: simulierte Malware-Angriffe analysieren, ganze Netzwerk-Segmente mit der Firewall abschirmen oder Systeme präventiv herunterfahren bzw. wiederstellen. - Red Team Assessment (RTA)
Mit einem Red Team Assessment wird das Incident-Response-Dispositiv als Ganzes trainiert. Dabei wird eine externe Firma für einen simulierten Cyberangriff engagiert und die Zusammenarbeit zwischen den Rollen/Teams trainiert.
- Krisenübung / Crisis-Exercise (CX)
In einer fünften und letzten Phase wird das das unternehmensweite Krisenmanagement in Bezug auf Cybersecurity-Vorfälle trainiert.
Der Aufwand für die Trainings steigt aber jeweils markant an (siehe Abbildung 2). Ein Prozess-Walk-Through kann mit sehr wenig Aufwand durchgeführt werden, während eine unternehmensweite Krisenübung eine riesige Vorbereitung benötigt.

Abbildung 2: Aufwand und Komplexität der verschiedenen Traingsarten.
Hermann Ebbinghaus lässt grüssen
Ein weiterer Grund für Trainings ist die menschliche Eigenschaft, Erlerntes wieder zu vergessen. Dieses Phänomen untersuchte Hermann Ebbinghaus bereits im 19 Jahrhunderts und erfand die Vergessenskurve. Nur durch ständiges Nutzen des Wissens behält man es, wobei jede Wiederholung das Intervall, nach welchem eine erneute Wiederholung nötig ist, vergrössert. Wir müssen somit nicht nur einmal, sondern wiederholt trainieren.
Ein einfaches Trainingskonzept muss her
Aus diesen Gründen empfehlen wir, ein einfaches Trainingskonzept zu erstellen. Dabei sind die involvierten Rollen/Teams sowie Trainingszeile, resp. die Trainingsarten, die entscheidenden Faktoren. Es muss aber berücksichtigt werden, dass einzelne Rollen sehr stark involviert sind (z.B. der Security Analyst bzw. der Incident Responder), während wiederum andere Rollen/Teams nur in Spezialfällen Aufgaben zu erledigen haben (bspw. das Senior Management bei einer Eskalation zu einem Major Incident). Die Trainings-Periodizität der Rollen/Teams sollten dementsprechend ausgelegt werden. Die Teams, die stark involviert sind, sollen mehr trainieren. Teams, welche nur marginal zum Einsatz kommen, sollen weniger trainieren.
Nun haben wir alle wesentlichen Punkte zusammengetragen. Nun müssen wir die Faktoren sinnvoll kombinieren und es resultiert ein einfaches Trainingskonzept. In Abbildung 3 ist ein beispielhaftes Trainingskonzept illustriert.
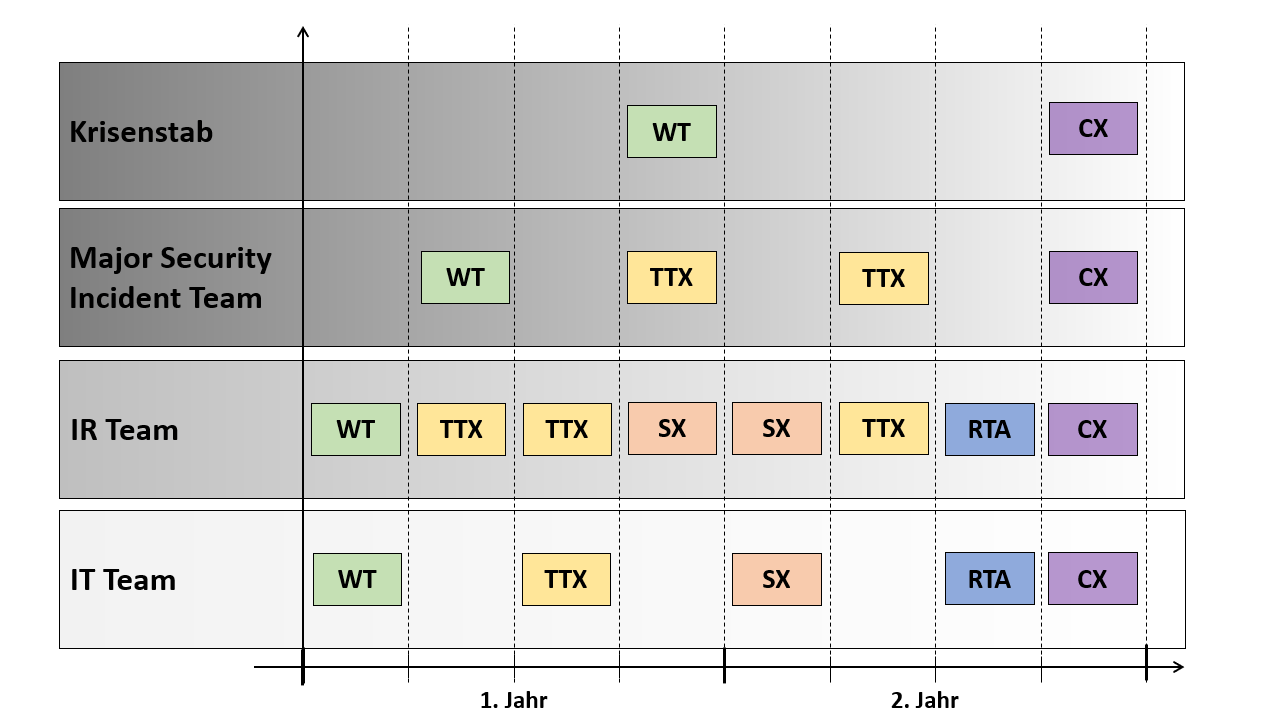
Abbildung 3: Beispielhaftes zweijähriges Trainingskonzept für die relevanten Incident Response Teams.
Nun gilt es die ersten Trainings zu planen und durchzuführen. In den kommenden Blogposts werden wir aufzeigen, was die Inhalte von möglichen Trainings sein können. Der zweite Blogbeitrag wird aufzeigen, wie man mit einem Prozess-Walk-Through und Tabletop-Übungen den Prozess in der Unternehmung etablieren kann. Der dritte Teil geht dann darauf ein, wie technische Betriebsabläufe mit Simulations-Übungen trainiert werden.
Der Beitrag Erhöhung der Cyber Resilience: Cybersecurity-Vorfälle richtig trainieren erschien zuerst auf Tec-Bite.

IoT/OT: Ein Ausblick auf den Zscaler Branch Connector

Zscaler Branch Connector, das lang erwartete Gegenstück zum Zscaler Client Connector, ist endlich verfügbar. Diese Komponente deckt nun auch die letzten Geräte ab, welche wir bis anhin nicht ohne Weiteres abdecken konnten: IoT und OT – sei es ein Messfühler, ein Scanner, ein Drucker oder doch ein Server. Üblicherweise konnten wir bis anhin auf diesen Geräten keinen Client Connector installieren oder die Installation war nicht praktikabel und so konnten wir wiederum diese Geräte nur bedingt via Zscaler absichern – bedingt deshalb, da wir in der Vergangenheit mittels GRE- oder eines IPSec-Tunnels Zscaler Internet Access (ZIA) verwenden konnten, aber z.B. nicht Zscaler Private Access (ZPA).
Mit dem Branch Connector ist dies nun möglich, wir können seither auch IoT- und OT-Geräte in unserem ZTNA-Konzept abbilden und dadurch insbesondere Legacy-Applikationen schützen und miteinander verbinden.
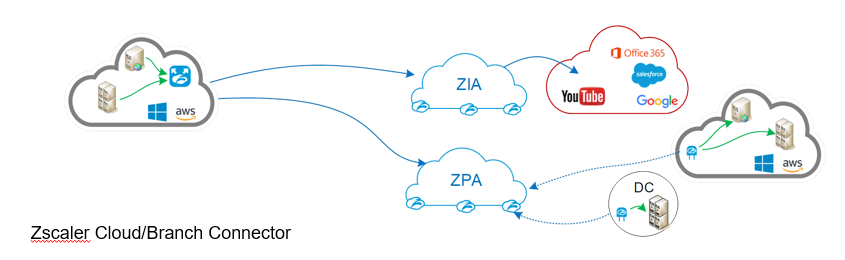
Zscaler Cloud und Branch Connector im Vergleich
Der Branch Connector ist dabei ein physisches Gerät, welches voraussichtlich per Ende des Jahres verfügbar ist, kann aber heute schon als virtuelle Maschine betrieben werden. Das Gegenstück in der Cloud (z.B. bei Azure oder AWS) ist der Zscaler Cloud Connector. Der Cloud Connector und der Branch Connector unterscheiden sich eigentlich gravierend nur in einer Funktion: Der Branch Connector ermöglicht ausserdem, den Zscaler App Connector (aus dem ZPA Feature) mitzubetreiben – was bei der Hardware-Komponente bei kleineren Lokationen, bei welchen keine Hardware mehr vorhanden ist, durchaus interessant sein kann.
Den Zscaler Branch Connector können wir in eine bestehende Umgebung dabei auf zwei Arten einbinden: Entweder als Default Gateway und Default DNS Resolver – oder wir können ihn als DNS Resolver einbinden, respektive als Forwarder Server für vorhandene DNS Resolver, wobei wir im Portal ein beliebiges Netzwerk-Range definieren, welches via DNS spezifische Ranges auflöst und dem Client zurückgibt. Entsprechend müssen dieses Ranges explizit an das Gerät geroutet werden. Es findet in beiden Fällen also eine Art «Hide NAT» statt – ähnlich, wie Sie es vielleicht schon aus ZPA vom Client Connector kennen –, sodass die reale IP des Zielsystems nie ersichtlich ist.
Durchsatz beim Branch Connector und Cloud Connector
Vom Durchsatz her kann der Branch Connector und Cloud Connector, je nach Sizing, bis zu 2 Gbits/s ermöglichen. Dabei können wir ähnlich wie beim Zscaler Client Connector als Forwarding stets folgende vier Methoden definieren:
Vom Durchsatz her kann der Branch Connector und Cloud Connector, je nach Sizing, bis zu 2 Gbits/s ermöglichen. Dabei können wir ähnlich wie beim Zscaler Client Connector als Forwarding stets folgende vier Methoden definieren:
- Für den zu schützenden Internet Traffic können wir diesen zu ZIA schicken
- Private Applikationen können wir via ZPA darüber erreichen
- Weiterhin können wir Ausnahmen definieren und Traffic direkt schicken
- Ungewollten Traffic können wir abschliessend an der Stelle verwerfen (drop)
Lizenziert wird der ganze Spass pro Workload (IP) und Volumen.
Einfaches Deployment
Das Deployment ist recht einfach – wir benötigen lediglich einen Account, um dort einen Deployment User und ein Deployment Template zu erstellen. Mit Hilfe dieser Parameter kann ein ISO File geschrieben und generiert werden, welches anschliessend der VM oder später an die Hardware entsprechend als physische CD-ROM oder als virtuelles Image angefügt wird. Mit diesen Daten konfiguriert sich der Connector selbständig und lädt entsprechende Software nach, um sich abschliessend mit dem kundeneigenen ZIA- und ZPA-Konto zu verbinden. Verwaltet wiederum wird der ganze Service in einem weiteren Portal, welches unter: https://connector.<cloudname>.net erreichbar ist.
Fazit
Wie praktikabel der Branch Connector und Cloud Connector im Betrieb «verheben», konnte ich leider nicht testen. In meiner Umgebung habe ich derzeit noch ein Bug, der damit zusammenhängt, dass ich eine eigene PKI bei ZPA betreibe, den ich anfangs des Jahres austauschen musste, da ein Intermediate Zertifikate lief. Dies hat jedoch zur Folge, dass ich derzeit keine neuen Konnektoren mehr komplett aufsetzen kann, da diese sich schlicht nicht als Client in ZPA «enrollen» können. Es bleibt also noch spannend …
Der Beitrag IoT/OT: Ein Ausblick auf den Zscaler Branch Connector erschien zuerst auf Tec-Bite.

E-Mail Security: Datenintegrität sicherstellen

In diesem Blogbeitrag möchte ich über verschiedene Möglichkeiten schreiben, wie Einzelpersonen und Organisationen ihre Datenintegrität unterstützen können.
Ein Datenintegritätsdienst erkennt in der Regel, ob Daten unbefugt verändert wurden. Es gibt zwei Möglichkeiten, wie Daten verändert werden können: versehentlich, durch Hardware- und Übertragungsfehler, oder durch einen absichtlichen Angriff. Viele Hardwareprodukte und Übertragungsprotokolle verfügen über Mechanismen zur Erkennung und Korrektur von Hardware- und Übertragungsfehlern. Der Zweck der Datenintegritätsüberprüfung ist die Erkennung eines vorsätzlichen Angriffs.
Es soll dabei lediglich festgestellt werden, ob Daten verändert wurden. Ein Datenintegritätsdienst zielt nicht darauf ab, den ursprünglichen Zustand der Daten wiederherzustellen, wenn sie verändert wurden. Das wäre auch sehr schwierig, wenn nicht unmöglich.
Bei Daten im internen Netzwerk können Zugriffskontrollmechanismen insofern zur Datenintegrität beitragen, als dass Daten nicht verändert werden können, wenn der Zugriff verweigert wird.
Wir konzentrieren uns hier auf Daten, welche über den problematischen Kanal eintreffen, nämlich über die E-Mails.
Doch wie lässt sich überhaupt feststellen, ob die Datenintegrität bei Mails verletzt wurde?
Was bedeutet Datenintegrität?
Beginnen wir mit einer grundlegenden Erklärung dessen, was Datenintegrität bedeutet. Datenintegrität bezieht sich auf die Fähigkeit einer Organisation oder eines Unternehmens zu gewährleisten, dass die Daten in ihrem Besitz vertraulich, vollständig und zuverlässig sind. Ziel ist es, dass jegliche Daten – beispielsweise Finanzdaten, Kundeninformationen oder vertrauliche Unterlagen – jederzeit geschützt und sicher sind. Eine der einfachsten Möglichkeiten, um die Datenintegrität zu fördern, ist die Verwendung eines E-Mail-Signatursystems.
E-Mail-Signierung
Mit einem Signatursystem können die Absender von E-Mails verifiziert, geplant und validiert werden, um sicherzustellen, dass die E-Mail nicht geändert oder manipuliert wurde. Abgesehen von E-Mail-Signaturen arbeiten viele Unternehmen auch mit E-Mail-Verschlüsselung. Eine E-Mail-Verschlüsselung ist ein Verfahren, bei dem die Informationen in einer E-Mail verschlüsselt werden, um zu verhindern, dass sie für unautorisierte Personen offengelegt wird. Wenn also eine E-Mail versendet wird, kann der Inhalt durch eine dritte Partei nicht gelesen oder verändert werden.
Verwendung von DKIM und SPF
Eine weitere Möglichkeit, die Datenintegrität zu unterstützen, ist die Verwendung von DKIM und SPF. DKIM (Domain Keys Identified Mail) ist ein Dienst, der es Organisationen ermöglicht, E-Mails zu verifizieren und zu validieren. DKIM basiert auf asymmetrischer Kryptographie und versieht Mails mit einer digitalen Signatur. Mit DKIM können Sie sicherstellen, dass E-Mails authentisch und nicht geändert werden. Das Sender Policy Framework (SPF) hilft, E-Mail- Administratoren dabei zu identifizieren, ob bestimmte E-Mail-Nachrichten von einem berechtigten Mailserver versendet wurden.
E-Mail-Verschlüsselungs-Gateway
Ein E-Mail–Verschlüsselungs-Gateway unterstützt verschiedene Verschlüsselungs-Standard-Technologien (wie S/MIME, TLS, Gateway-to-Gateway-Verschlüsselung, kombinierte Verfahren oder zusätzlich eigene Verschlüsselungsverfahren). So wird der verschlüsselte Versand zu 100% gewährleistet. Der Absender wird dadurch befähigt, auch einem gänzlich unbekannten Empfänger ohne vorherigen Schlüsselaustausch eine verschlüsselte E-Mail zu schicken. Bei Unsicherheit über das angewandte Verschlüsselungsverfahren des Empfängers, reicht bei einem Gateway-Anbieter wie SEPPmail das manuelle Anstossen einer Verschlüsselungsoption über einen Outlook Button. In diesem Fall entscheidet sich z.B. SEPPmail für ein eigenes Verschlüsselungsverfahren.
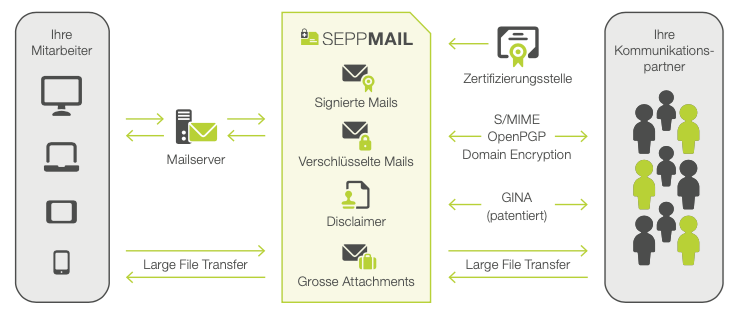
Beispiel: Ein Secure E-Mail Gateway von SEPPmail
Erhält Bob die Mail von Alice, welche über das Gateway in einen HTML-Container verpackt wurde, muss Bob, damit er die Verschlüsselung dechiffrieren kann, sich lediglich über ein Login des Gateway-Dienstes authentisieren. So benötigt auch der Empfänger für das Entschlüsseln einer sicheren Antwort bloss einen beliebigen E-Mail-Client. Durch eine Rule Engine wird bestimmt, wie jede einzelne E-Mail verarbeitet wird. Es greifen auch weitere Funktionen wie Spam- und Virenschutz. Konfigurierbar ist ein solches Regelwerk meist über eine browserbasierte Administratoroberfläche, damit sich für jedes Unternehmen spezifische Security Rulesets anpassen lassen. Das Gateway überprüft in jedem Fall, ob das gelernte Zertifikat gültig ist und ob an der E-Mail etwas geändert wurde, erkenntlich an einer Subject-Kennzeichnung wie «signed OK» bzw. «signed INVALID».
Auf das neue Datenschutzgesetz vorbereitet sein
Das revidierte Schweizer Datenschutzgesetz tritt am 1. September 2023 in Kraft. Das Hauptziel des Gesetzes besteht darin, die Transparenz und den Schutz der persönlichen Daten von betroffenen Personen zu stärken. Bei einem Verstoss drohen Bussgelder von bis zu 250’000 Franken.
Wichtig zu verstehen: Im revDSG werden nicht die Unternehmen zur Kasse gebeten, sondern natürliche Personen, z.B. der CISO oder IT-Leiter. Das neue Datenschutzgesetz stellt insbesondere höhere Ansprüche an die Datenintegrität bei Personendaten und besonders schützenswerten Personendaten, die in noch stärkerem Umfang als bisher durch technische Massnahmen geschützt werden müssen. Zu den «gewöhnlichen» Personendaten gegenüber besonders schützenswerten Personendaten (wie Daten über die Gesundheit, politische und weltanschauliche Ansichten) zählen beispielsweise der Name, die Adresse oder das Geburtsjahr der jeweiligen Person. Ein hohes Risiko eines «Profilings» bestünde für die Persönlichkeit oder die Grundrechte der betroffenen Person insbesondere bei einer Verknüpfung von Daten, die eine Beurteilung wesentlicher Aspekte der Persönlichkeit einer natürlichen Person erlauben würde (Kapitel 2. Abs. 1, Art. 5g). Eine wesentliche Rolle spielt daher eine datenschutzkonforme E-Mail-Kommunikation.
Ausblick
Ich hoffe, dass Sie jetzt eine bessere Vorstellung davon haben, wie Einzelpersonen und Organisationen ihre Datenintegrität unterstützen können, indem sie Mailsignaturen und Mailverschlüsselung sowie DKIM und SPF verwenden. Ein weiteres Thema wäre die Integritätsprüfung der Daten im internen Netzwerk.
Auf unserem IT-Security Blog Tec-Bite werde ich Sie weiter über Themen wie Montoring und Logging, Datenschutzmassnahmen und E-Mail-Governance auf dem Laufenden halten. Ich freue mich, Ihnen bei der Förderung Ihrer Datenintegrität zu helfen.
Weiterführende Links:
Der Beitrag E-Mail Security: Datenintegrität sicherstellen erschien zuerst auf Tec-Bite.

Netzwerksegmentierung ohne Netzwerk-Umbau

Ohne ausreichende Netzwerksegmentierung haben Angreifer oft ein leichtes Spiel, sich seitlich (Lateral Movement) im Netzwerk zu bewegen. Aufgrund dieser Schwachstelle können Cyberkriminelle ohne grossen Widerstand auf Kronjuwelen wie Domain Controller, CRM- oder ERP-Systeme zugreifen, sobald sie sich im selben Netzwerksegment befinden. Wie sich eine Netzwerksegmentierung umsetzen lässt, will ich im Folgenden anhand eines Usecase mit Illumio aufzeigen.
Um die Seitwärtsbewegung des Angreifers zu verhindern, ist es unerlässlich, dass Unternehmen ihr Netzwerk segmentieren. Allerdings scheuen sich viele vor dem damit verbundenen Aufwand und den zusätzlichen Kosten. Oftmals erfordert dies umfangreiche Änderungen im Subnetting, Routing und bei der IP-Adressierung der Systeme.
Da der Datenverkehr durch die Firewall gesteuert wird, erhöht sich dieser durch die Änderungen enorm und so kommt es oft vor, dass man mit der vorhandenen Infrastruktur an die Grenzen kommt. Die Firewall muss dann durch eine leistungsstärkere Version oder mehrere Firewalls ersetzt werden, um den neuen Anforderungen gerecht zu werden und den Datenverkehr zu bewältigen.
Gibt es eine Alternative?
Illumio Core ermöglicht eine Segmentierung bis hin zur Mikrosegmentierung der Server- und Endpoint-Systeme, ohne Änderungen an der Netzwerk- oder Firewall-Infrastruktur vorzunehmen.
Das Produkt besteht aus zwei Schlüsselkomponenten: der Policy Compute Engine (PCE) und dem Virtual Enforcement Node (VEN).
Die PCE ist die Serverseite der Illumio-Plattform und ist entweder als SaaS oder On-Prem verfügbar. Sie fungiert quasi als Controller für die Policies und als zentraler Manager für den VEN.
Der VEN ist der Agent, der auf den Systemen (bei Illumio als «Workloads» bezeichnet) installiert wird und mit der PCE kommuniziert. Sobald der VEN auf dem System installiert und aktiviert (bzw. «paired») ist, wird dieser als «Managed Workload» bezeichnet, da er die native Host Firewall verwalten kann.
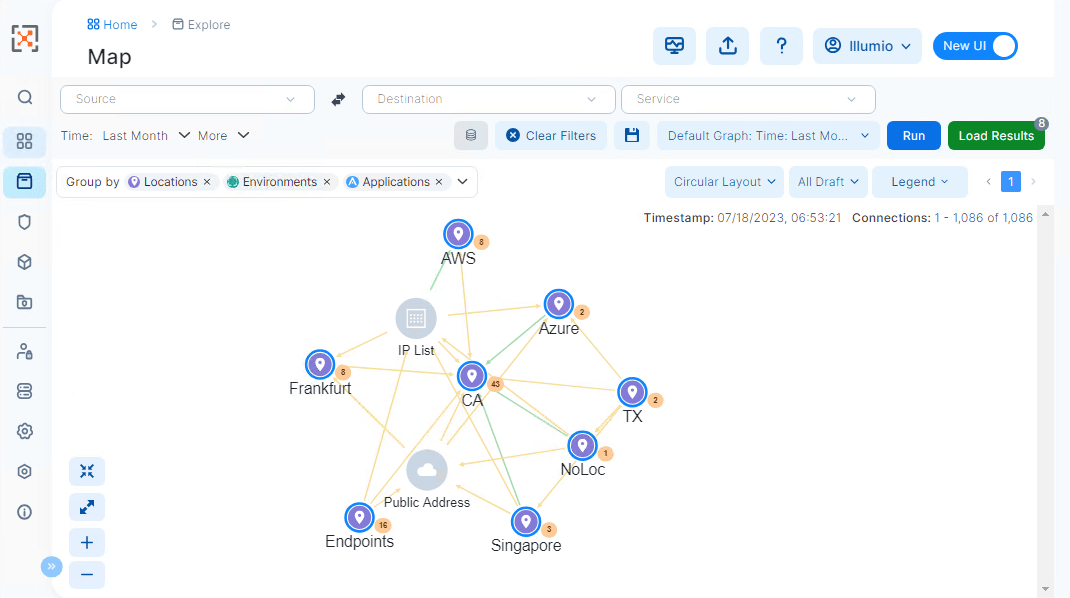
Die Illumio PCE Web Console: MAP-Ansicht
Es können aber auch Systeme in der PCE erstellt werden, bei der kein VEN installiert werden kann, wie z.B. IoT Devices oder Systeme nicht unterstützter Betriebssysteme. Diese werden als «Unmanaged Workload» erstellt. Da kein VEN Agent auf jenen Hosts installiert ist, kann auch nicht die native Host Firewall verwaltet werden. Jedoch lassen sich Policies von und zu einem «Managed Workload» erstellen, da die Policy auf dem VEN-installierten System «enforced» wird.
Illumio wird in erster Linie über eine grafische Weboberfläche, die sogenannte PCE Web Console, verwaltet. Zusätzlich verfügt sie über eine starke REST-API, die es ermöglicht, gängige Verwaltungsaufgaben durchzuführen. Dadurch können beispielsweise umfangreiche Workload-Gruppen einfach automatisiert verwaltet werden, anstatt jeden einzelnen Workload separat zu bearbeiten.
Kann Illumio Core eine Netzwerk Firewall ersetzen?
Illumio verfügt nicht über die umfassenden Fähigkeiten einer modernen Next Generation Firewall (NGFW), die den Datenverkehr mit Features wie Intrusion Prevention System (IPS) oder SSL Inspection auf tieferer Ebene analysieren kann, um Bedrohungen zu erkennen und zu blockieren.
Das Produkt legt seinen Fokus nicht auf die Erkennung von Bedrohungen, sondern konzentriert sich darauf, die Ausbreitung von Bedrohungen zu verhindern. Dabei macht es sich die nativen Host-Firewall-Funktionen des Betriebssystems eines Servers zunutze, um die Netzwerksegmentierung umzusetzen.
Dies bedeutet, dass die Kommunikation zwischen Anwendungen und Systemen auf der kleinsten Einheit des Netzwerks kontrolliert werden kann. Im Gegensatz zu einer NGFW (Next Gen Firewall), die auf Netzwerkebene agiert, konzentriert sich Illumio Core darauf, die Kommunikation auf Anwendungsebene zu steuern.
Kann ich nicht dasselbe wie mit Illumio Core auch einfach mit einer Netzwerk-Firewall erreichen?
Natürlich ist das zweifellos möglich, aber zu welchem Preis? Wenn beispielsweise eine Mikrosegmentierung der Server in einer DMZ angestrebt wird, erfordert dies umfangreiche Anpassungen an Subnetzen und der IP-Adressierung. Um den Datenverkehr über die Firewall zu kontrollieren, müssen für jeden Server neue, separate kleine Subnetze eingerichtet werden. Jeder Wechsel eines Systems von einer Zone in eine andere erfordert eine Änderung der IP-Adresse.
Solche Änderungen können erhebliche Auswirkungen haben und bedeuten sehr viel Aufwand für die Restrukturierung des Netzwerks. Beispielsweise könnten Anwendungen, die bisher die IP-Adresse eines Servers anstelle des Fully Qualified Domain Name (FQDN) für die Kommunikation verwendet haben, nach dem Wechsel nicht mehr funktionieren. Daher ist es wichtig, solche Anpassungen mit grosser Vorsicht durchzuführen. Dies führt dazu, dass die Implementierung eines traditionellen Zonenkonzepts in der Regel als langfristiges strategisches Vorhaben betrachtet wird.
Label-basiertes Policy Management
Des Weiteren müssen für jede neue Zone, in diesem Fall für einzelne Server Verbindungen, Policies geschrieben werden, um nur den legitimen Datenverkehr zu erlauben. Dies führt zu einer zunehmend komplexen Verwaltung und Übersichtlichkeit, da sich die Firewall Rules um ein Vielfaches multiplizieren.
Mit Illumio Core hingegen wird wie bereits erwähnt am Netzwerk, den Subnetzen sowie IP-Adressierung nichts verändert. Es kann somit bestens in die bestehende Infrastruktur integriert werden.
Illumio Core verwendet ein Label-basiertes Policy-Modell, was bedeutet, dass es im Gegensatz zu herkömmlichen Firewall-Lösungen keine Verwendung von IP-Adressen oder Subnetzen bei der Rule-Erstellung verwendet. Auf diese Weise können die Workloads kategorisiert werden und so lässt sich die Policy schneller erstellen. Es basiert dabei auf vier Labels: Role, Application, Environment und Location. Zusätzlich können beliebige weitere Dimensionen, wie z.B. Business Unit, Risikoklasse oder andere Objektdaten, an Objekte gehängt werden, um sowohl auf der Map als auch in der Policy die Möglichkeit zu haben, granular nach diesen Kriterien zu filtern.
Hauptsächlich werden die Policies aus Sicht der Applikation geschrieben, also applikationszentrisch definiert. Der Scope definiert dabei den Bereich, bestehend aus den Labels, zu deren Workloads verschiedene Applikationen gehören.
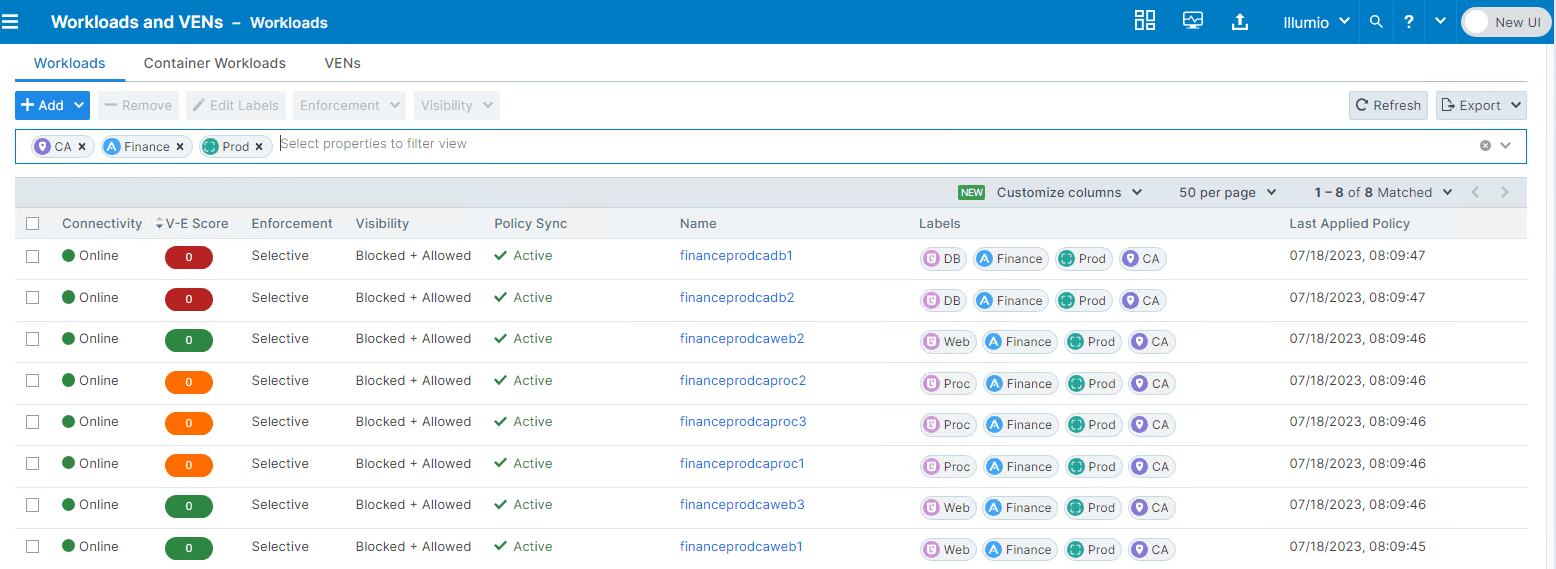
Workloads (Systeme) werden mit Labels definiert.
Policy-basierten Datenverkehr in einer Map einsehen
Ein weiterer Vorteil von Illumio bieten die vielen Möglichkeiten, den Datenverkehr zu visualisieren; eine davon ist z.B die App Group «MAP», welche den Datenverkehr innerhalb, von und zu einer Applikation, aufzeigt und sogar die Möglichkeit bietet, gleich direkt aus der Map eine Rule zu erstellen, um einen bestimmten Flow in der Policy freizugeben.
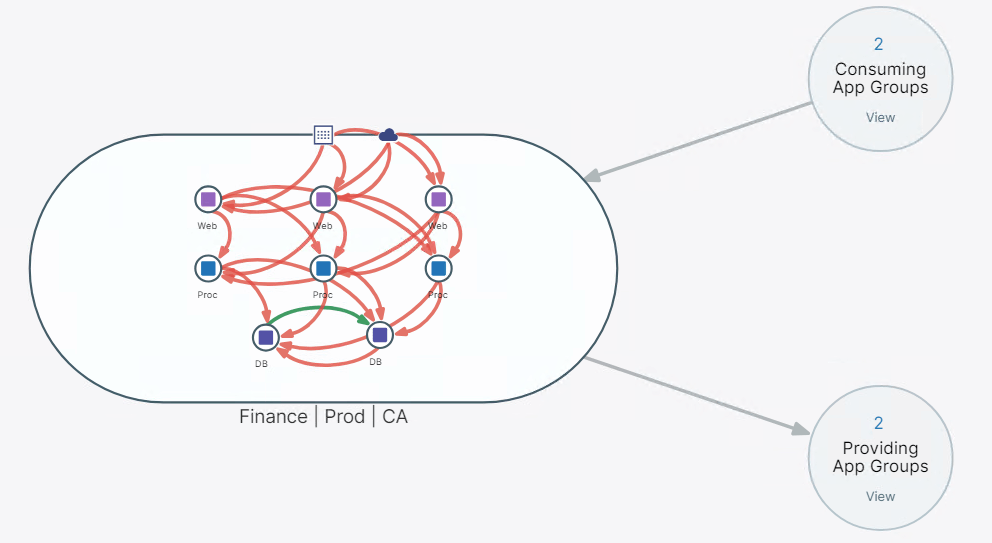
Darstellung der Applikation Finance (mit Prod Environment und CA Location) in der App Group MAP
Fazit
Illumio Core ersetzt zweifellos keine Firewall, insbesondere keine Perimeter Firewall, und das ist auch nicht sein Ziel.
Dennoch ist es eine wertvolle Ergänzung für Unternehmen, die bisher noch keine umfassende Netzwerksegmentierung umgesetzt haben. Ein typisches Beispiel wären dabei Unternehmen mit einer traditionellen flachen Architektur, die üblicherweise aus einer DMZ, einer Server- und einer Clientzone bestehen.
Ein weiteres Anwendungsbeispiel sind auch Unternehmen, die bereits seit längerem die Vorteile der Mikrosegmentierung erkannt haben, bisher jedoch von der vermeintlichen Komplexität bei der Umsetzung mit bisher traditionellen Methoden abgeschreckt wurden.
Weitere Stärken von Illumio Core liegen in der Visibilität, die es Unternehmen ermöglicht, den Datenverkehr im Netzwerk detailliert aufzuzeigen und so potenzielle Sicherheitsrisiken schnell zu erkennen. Zusätzlich bietet Illumio Core eine flexible und skalierbare Lösung, die es Unternehmen ermöglicht, ihre Sicherheitsmassnahmen schrittweise anzupassen und zu erweitern, ohne dabei die Betriebseffizienz zu beeinträchtigen.
Einführung in Zero Trust – ein Paradigmenwechsel
Die Risiken von ChatGPT kennen
Wie das Beste aus Check Point Firewalls herausholen: Neue Funktionen und Optimierungsmöglichkeiten
Der Beitrag Netzwerksegmentierung ohne Netzwerk-Umbau erschien zuerst auf Tec-Bite.

Mail-Authentisierungsverfahren – die Rolle von SPF, DKIM und DMARC

In einer früheren Reihe von Blogartikeln habe ich die Mail-Authentisierungsverfahren SPF (Sender Policy Framework), DKIM (Domain Keys Identified Mail) und DMARC (Domain-based Message Authentication, Reporting and Conformance) behandelt und ihre begrenzte Wirksamkeit gegen Spam und Phishing kritisiert. Dabei habe ich über die verschiedenen Probleme bei Fehlkonfigurationen, Mail-Weiterleitungen und Mailinglisten gesprochen.
Meine Meinung zu diesen Verfahren habe ich jedoch mittlerweile etwas revidiert, da ich einen sinnvollen Anwendungszweck entdeckt habe: ActiveGuard von xorlab.
Mail-Authentisierungsverfahren mit ActiveGuard
Wir haben schon früher über das Mail Security Gateway «ActiveGuard» von xorlab berichtet. Während viele andere Mail Gateways sich auf den Reputationsscore des einliefernden Mail Servers, das Alter der Absenderdomäne und den Inhalt der Mails in Bezug auf Spam oder Phishing konzentrieren, geht ActiveGuard darüber hinaus. Es betrachtet auch die regelmässige Kommunikation zwischen Absendern und Empfängern, um zu lernen, welche E-Mails für eine bestimmte Firma oder Organisation relevant sind.
Beispiel: Ich tausche regelmässig Mails mit Personen bei xorlab aus. Daher erkennt ActiveGuard diese regelmässige Kommunikation und lernt die Verkehrsbeziehung zwischen uns. Es erkennt auch die Beziehung zwischen unseren Mail-Domänen. E-Mails von Domänen mit einem hohen «Beziehungs-Score» werden als wichtiger und weniger spamverdächtig betrachtet als Nachrichten von Domänen, mit denen wir noch keinen Kontakt hatten.
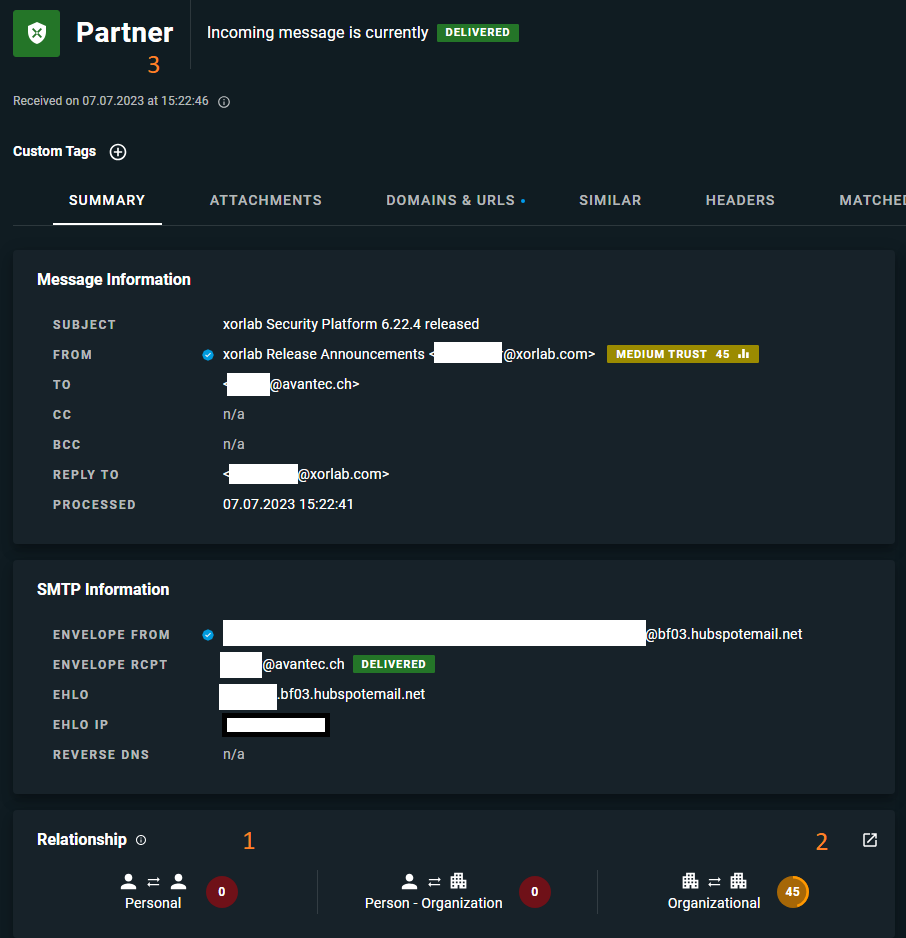
Hier in diesem konkreten Fall hat uns die Firma xorlab einen Newsletter geschickt und über ein neues Release informiert. Da ich jedoch nie eine Mail an die Newsletter-Absenderadresse geschickt habe, gibt es keinen persönlichen Beziehungsscore (1). Aber unsere Firmen haben einen regen Austausch, daher besteht ein «trust» auf Organisationsebene (2). ActiveGuard erkennt xorlab als Partner (3) und behandelt die Mails entsprechend.
Allerdings ist ein Mail von diesem Partner nur dann wichtig und vertrauenswürdig, wenn es tatsächlich von xorlab stammt und die Absenderadresse nicht gefälscht wurde (was bekanntlich einfach möglich ist). Hier kommen nun die Mail-Authentisierungsverfahren ins Spiel: Nur wenn SPF und DKIM korrekt sind, gilt der Absender als nicht gefälscht, und wir können uns auf den «Beziehungs-Score» für die Klassifizierung der Mail verlassen.
In diesem Fall stimmt aber die DKIM-Signatur.

Und auch SPF ist korrekt.

(ActiveGuard hat auch korrekt erkannt, dass die Mail von einem berechtigten Newsletter-Versender stammt und nicht von xorlab selbst.)
Um zu wissen, wer mit wem kommuniziert und so ein korrektes Kommunikationsnetzwerk aufzubauen, ist die Authentisierung der Mail-Domänen also wichtig.
Daher rufe ich alle dazu auf, SPF, DKIM und DMARC zu implementieren!
Leider gibt es da noch einiges zu tun:
Der CH Resilience Report von Hardenize zeigt, dass in der Schweiz von den Top 1000 Domains zwar 88% SPF Records veröffentlicht haben, aber nur 18% DMARC im aktiviert haben.

Quelle: hardenize.com/dashboards/ch-resilience, aufgerufen am 14.07.2023
In einer ruhigen Minute plane ich eine umfangreichere Analyse der Schweizer Domänen. Stay tuned.
Der Beitrag Mail-Authentisierungsverfahren – die Rolle von SPF, DKIM und DMARC erschien zuerst auf Tec-Bite.